

درود بر دوستان خوبم.در این برسی سعی میکنم به طور مختصر و ساده معماری بسیار جدید AMD رو توضیح بدم و اینکه چرا AMD بعد از این همه مدت تصمیم گرفت یک معماری کاملا نوین در نسل اینده پردازشگر های گرافیکیش استفاده بکنه.
پس در ابتدا بهتره ببنیم معماری گذشته amd/ati از کجا شروع شده :
تاریخچه:
شرکت ATI اولین شرکتی بود که اولین نسل Unified shader هارو در اولین پردازشگر گرافیکی مبتنی بر این تکنولوژی استفاده کرد و این gpu چیزی نبود جزء Xenos پردازشگر گرافیکی کنسول xbox 360 .با اینکه از لحاظ توان محاسباتی از رقیب RSX اون در PS3 کمی ضعیفتر بود اما به خاطر Data throuput پیشرفته نسل اینده شیدر میشه گفت به مراتب عملکرد بهتری داشت.(در کل xenos انصافا عملکرد خیلی بهتری نسبت به RSX داشت و همین باعث شد ضعف های Xenon پردازنده xbox رو در مقابل cell کنسول ps3 پوشش بده.
طراحی اولین نسل unfied shader ها بر اساس معماری VLIW بود.البته نه به شکل Stream processor های فعلی و هر shader processor هماندد یک SIMD یا steam processor شامل 5 پردازنده شیدر عمل میکرد و در هر سیکل 10 عمل رو انجام میداد.
دومین نسل unified shader ها که درواقع اولین نسل pc هم محسوب میشن در R600 به کار رفتن که درواقع همون نسل HD2000 برند ATI محسوب میشد.
در این نسل هم انویدیا اولین نسل Unified shader های خودشو معرفی کرد که با اختلاف بسیار زیاد از hd2900 برتر بود و باعث شد انویدیا تقریبا تا 2.5 نسل درجا بزنه چون اختلاف به حدی شدید بود که amd تا نسل R700 که یک طراحی فوقولاده داشت نتونست پاسخ قدرت بیچون و چرای 8800GTX رو بده.
طراحی Stream processor ها یا همون SIMD ها در نسل 4000 بسیار بهتر شد و VLIW 5 به خوبی تونست انویدیا رو به چالش بکشه.
AMD/ATI این طراحی رو تا همین نسل فعلی که جزایر شمالی باشه ادامه دادن مگر باتغییراتی و بهنیگی در عملکرد SIMD ها که باعث شد AMD بتونه در Double precision و پیاده سازی اندک متد tlp برای اولین بار موفق باشه و عملکرد gpu های خودشو بهبود ببخشه.
اما نسل اینده gpu های amd که ما اونو جزایر جنوبی میخونیم دیگه کمتر برای پردازش صرف کاملا موازی نسل گذشته به کار میره بلکه در واقع amd پردازشگری رو طراحی کرده برای compute :
Next Generation of AMD Architecture

همونطور که میدونید سیاست AMD برای نسل اینده تنها و تنها یک شعار مشخصه و اون هم اینه که THE future is fusion .سرمایه گذاری اصلی amd برای اینده ترکیب پردازنده و gpu هست و به گفته amd نسل ایندرو تغییر میده وکلا بازی به نفع APU ها تغییر میده.
اولین نسل ارئه شده هم که در حال حاظر موجوده اما به نظر من هنوز برای همکاری قدرت بالای پردازشی GPU و قدرت کنترلی CPU زوده چون GPU ها و CPU نمیتونن به طور کامل با هم ارتباط پردازشی داشته بشن و از طریق یک NB که به صورت SOC در پردازنده هست با هم ارتباط دارن.(در واقع هنوز خیلی زوده به APU های فعلی بگیم یک APU واقعی بلکه همون System on chip بگیم برازنده تره و نکته اینه که پردازنده همکار GPU در LIANO از نسل K.10 یا 10.5 از جنس Shanghai هست و ما هنوز مفهوم حقیقی apu رو از amd باید در نسل های بعدی ببنیم)
سرمایه گذاری اصلی AMD برای نسل اینده بر روی APU هاست ونه تنها پردازش های گرافیکی صرف (بر عکس دو برند رقیب که هرکدوم به طور تخصصی بر روی یک زمینه در حال پیشرفت هستن) بلکه برای محاسبات COMPUTE هم هست.
هدف گذاری نسل اینده GPU های AMD علاوه بر هدف گرافیکی هدف محاسباتی COMPUTE به این منظوره که توسعه دهندگان علاوه بر بهره گیری از توان گرافیکی GPU ها بتونن از توان محاسباتی بسیار بالای اونها برای عملیات های محاسباتی استفاده کنن.( به صورت تئوری توان محاسباتی یک GPU میتونه تا بیش از 200 برابر یک CPU هم باشه و قصد AMD به کار گیری این توان محاسباتی در محاسبات مربوط CPU هست یا استفاده از توان کنترلی CPU برای برنامه ریزی task ها برای ارسال به واحد های پردازشی gpu برای سرعت بخشیدن به عملیات پردازشی هست)
amd در حال حاظر برای این مهم معتقده که معماری vliw اصلا گزینه مناسبی برای همکاری با cpu نیست و نیازمند یک معماری متفاوت برای رسیدن به این هدف میباشد.
amd نسل اینده معماری پردازش گر های گرافیکی خودش رو GCN که اختصار Graphic core next هست نام گذاری کرده که در ادامه به برسی اون میپردازیم:
Graphics Core Next
همونطور که عرض کردم GCN نام معماری نسل اینده پردازشگر های گرافیکی AMD هست که برای دومنظور پردازشهای گرافیکی و محاسبات طراحی میشود.در واقع این معماری برای اینده APU ها است و به طور دقیق برای پردازش های گرافیکی طراحی نشده به همین دلیل پیشبینی میشه در زمینه پردازش های گرافیکی نتونه به طور مستقیم و کامل با کپلر نسل اینده پردازشگر های گرافیکی انویدیا مقایسه بشه.(البته در اینجا این نکته لازمه گفته بشه که معماری انویدیا هم برای محاسبات یا همون COMPUTE بسیار بهینه بود و به همین خاطر در ابر کامپیوتر های معروف به صورت گسترده از اون استفاده میشد و شاید معماری جدید AMD باعث بشه که قدرت مطلق انویدیا در این عرصه تموم بشه ومعماری جدید AMD بتونه به خوبی با انویدیا رقابت کنه)
در کنفراس AFDS 2011 که معادل GTC انویدیا و IDF شرکت اینتل هست AMD این حقیقت رو عنوان کرد که در نسل اینده APU ها بولدوزر نمیه اول بوده و GCN نیمه دوم APU هاست و این دو در اینده درکنار هم درس خوبی به رقبا از هردونظر پردازش های گرافیکی و محاسبات میدن(خدا به داد INTEL و انویدیا برسه
 )
)خوب حال بریم سر برسی معماری که متاسفانه مطمئن هستم بسیار از دوستان به این بخش علاقه ای ندارن و این مطالبی رو که در اینده مینویسم مطالعه نمیکنن چون اگر داشتن لاقل یک مقدار در این حوضه بحث میکردن.
توصیف معماری VLIW که AMD در GPU های نسل فعلی و گذشته خودش استفاده میکرد:
بنیادی ترین واحد پردازشی مستقل نسل فعلی و قبلی AMD رو ما Streaming processor میشناسیم که در حال حاظر به اون SIMD هم میگن و در گذشته به اسم STRAMING PROCESSING UNIT یا به اختصار SPU میگفتیم.
هر SPU خود متشکل از چند واحد پردازشی و منطق ALU که پردازنده شیدر هم میخوندیم (Shader processor) تشکیل شده و بر اساس معماری VLIW 5 در گذشته یا VLIW 4 در نسل جدید در SPU ها یا SIMD ها قرار گرفتن.نکته:(البته AMD اسم اصلی هر ALU رو Radeon core میخونه اما چون کمتر استفاده میشه من همون sp یا پردازنده شیدر میخونم)
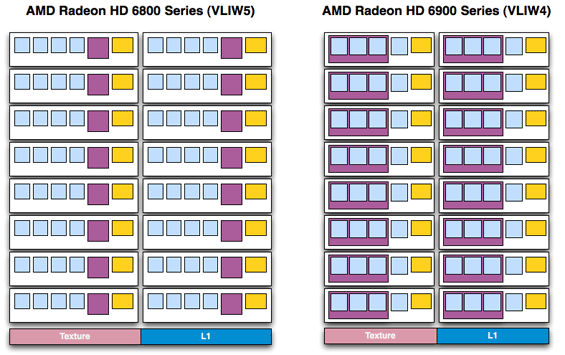
پردازنده های radeon core همونطور که گفتم میتونن بر اساس معماری VLIW 5 هماندد شکل زیر در SIMD یا SPU قرار بگیرن:

یا میتونن بر اساس معماری VLIW 4 که در 6900 استفاده شد در Streaming processor unit قرار بگیرن:
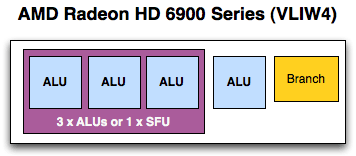
که برای مقایسه بهتر قرار گرفتن SPU ها میتونید شکل زیر رو درنظر بگیرید:
در واقع معماری VLIW به این منظور که برتری در اجرا و پردازش تعداد زیادی عملیاتهای که در یک Task مشابه به صورت موازی شکسته شدن و به گروه های کوچک تر که اونهارو wavefronts میخونیم طراحی شدن.(نیازه که یکباره دیگه این جملرو تکرار کنید تا دقیق متوجه بشید:mrgreen
هر wavefronts خود شامل یک گروه 64 تایی از پیکسل ها و مقادیر pixels/values به همراه دستور العمل هایی هست که باید روی پیکسل ها و مقادیر اونها اجرا بشن.در یک wavefront یک گروه 4 یا 5 تایی دستورالعمل روی pipe ها پایین میان و این 5 دستورالعمل به طور کامل غیر وابسته به هم هستن که اجازه میده هر radeon core یا alu به صورت جدا دستورالعمل هارو پردازش کنه(هریک جدا گانه توسط یک دستورالعمل تغذیه میشن)
همونطور که در این تاپیک من نحوه محاسبه توان محاسباتی پردازش گر های گرافیکی amd رو انجام دادم دیدیم به صورت تئوری به طور مثال HD5870 تا 2.72 ترافلاپس در Single precision یا 545 در double precision قدرت پردازش دارد.درصورتی که برای انویدیا این عدد به لحاظ تئوری بسیار کمتره و مثلا برای gtx480 برای dp تقریبا کمتر از 1/3 در مقایسه با hd5870 هست.
پس اینجا این سوال پیش میاد که چه عاملی سبب میشه این همه از توان پردازشی HD5870 به هدر برود؟؟ برای رسیدن به جواب ادامه مطلب رو مطالعه کنید:
همونطور که گفتم درصورتی به طور مثال در vliw 5 هر 5 عدد radeon core تغذیه میشن و قابلیت پردازش در نهایت توانایی رو دارن که 5 دستور العمل به صورت غیر وابسته یا non-interdependent باشن.اما در واقعیت چنین نیست و اکثر دستور العمل ها به دستورالعمل دیگری وابسته هستن پس بنابراین نمیتوانن توسط radeon core ها همزمان اجرا شن.
برای درک بهتر به تصویر زیر نگاه کنید:
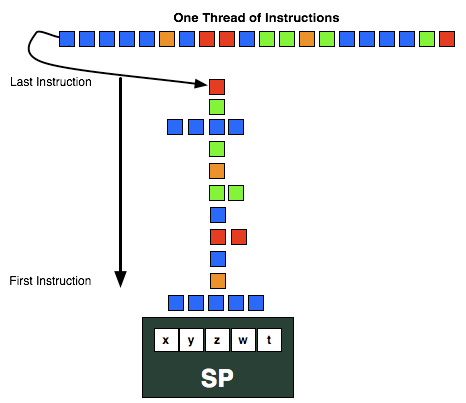
در رشته بالا ما یک ترد از دستورالعمل ها رو میبینیم که به صورت پشته در یک ثبات ذخیره شدن.(اخرین دستور العمل ها اولین دستور العمل اجرایی هستن)
در تصویر ما یک پردازشگر جریانیstreaming processor بر مبنای vliw 5 مبینیم که 5 عدد radeon core دارد.در پشته ما 5 دستور العمل غیر وابسته هم نوع میبینیم که همزمان در داخل 5 radeon core پردازش میشن.اما در مرحله بعد ما یک دستورالعمل زرد رنگ را میبینم که وابسته هست بنابر این نمیتواند همزمان با دستوراعمل های دیگر پردازش شود و به همین خاطر 4 عدد از alu ها یا همون radeon core ها بیکار هستن.این اعمال انجام میشود تا باز به دو دستور العمل غیر وابسته همنوع قرمز رنگ میرسد پس در اینجا 2 alu مشغول به پردازش میشن و 3 تای انها بیکار میمانند. مرحله بعد باز یکی و باز به سبز رنگ 2 تایی غیر وابسته میرسد پس همزمان 2 ترد پردازش میشن تا باز به 4 دستور العمل غیر وابسته همنوع میرسد.پس در اینجا 4 alu مشغول به کار میشن و تنها 1 از alu ها بیکار میماند.
نتیجه:
همونطور که دیدم تنها در صورتی میتوان از تمام قدرت پردازشی spu ها که شامل 5 هسته radeon core هستن استفاده نمود که همه ترد ها ی پردازشی به صورت زیر باشن:
1:اولا ترد ها به صورت دستورالعمل های 5 تایی همنوع باشن.و به صورت متداول تکرار بشن(5تا 5تا)
2:دوما همه دستورالعمل های 5 تایی غیر وابسته باشن.(منظور از غیر وابسته بودن اینه که انجام دستور العمل نیاز به اجرای دستورالعمل دیگری پیش از ان نباشد)
برای مثال: به عملیات زیر دقت کنید
1. e = a + b
2. f = c + d
3. g = e * f
فرض کنید میخواید رابطه بالارو محاسبه کنید.رابطه اول و دوم به هم ربطی ندارن و میتونن جدا از هم پردازش بشن اما رابطه سوم بستگی مستقیم به روابط 1 و 2 داره.پس تا رابطه 1 و 2 انجام نشن رابطه 3 قابل انجام نیست.
این مفهوم به دنبال اینه که ببنیچه تعداد از عملیت ها به هم نامربوط هستن تا بشه اونهارو به صورت موازی(چون ربطی به هم ندارن) پردازش بشن.بعد برن سراغ عملیات هایی که بستگی به نتیجه این محاسبات داشتن.
در دنیای واقعی پردازش ها بسیار از دستورالعمل ها به صورت وابسته و غیر همنوع هستن(32bit fp یا 64bit fp ..24bit integer .....) درواقع بسیار از توان محاسباتی SPU های AMD در مقایسه با انویدیا به هدر میرود.به همین علت در GPGPU هسته های کودا انویدیا بسیار بسیار موفق تر از معادل AMD هستن و این رو ما به وضوح در Quadro ها ی انویدا میبینیم.
amd پس از برسی داد های فعلی دید که داده های بهینه به صورت دستورالعمل های همنوع و غیر وابسته بعد از نسل dx9 کمتر و کمتر میشه بنابر این پس از تحقیقات خود به این نتیجه رسید که بهتره vliw shrink رو اعمال کنه بنابراین VLIW 4 ایجاد شد.
در واقع VLIW 4
اولا: در محاسبات DP بسیار بهتر از VLIW 5 عمل میکند چون عملا SFU از اجرای DP 64 bit عاجزه بنابر این تعداد زیاد SPU هایی که در 6900 هست با عث میشه 672 Gflops توان محاسبتی dp در مقابل 545 ه 5800 نسل قبل داشته باشه.
دوما: کمتر بودن عرض vliw یعنی 4 بجای 5 باعث میشه احتمال هدر رفتن توان spu ها یا همون SIMD ها کمتر اتفاق بیوفته.
------------------------------------
امیدوارم با این مرور سریع دوستان اولا علت استفاده نشدن از تمام توان محاسباتی AMD رو درک کرده باشن و ثانیا با کلیت کار نسل گذشته معماری AMD اشنا شده باشن تا بعد از تشریح عملکرد نسل بعد بتونن مقایسه با نسل قبل داشته باشن.
تشریح نسل اینده معماری AMD : Graphic core Next
بزرگترین و اساسی ترین مشکلی که برای جلورفتن معماری vliw وجود داشته اینه که VLIW برای داده های گرافیکی فوقولاده هست.اما برای محاسبات Compute که نقشه راه amd برای APU ها است اصلا مناسب نیست.
درواقع هدف amd اینست که یک پردازشگری رو در کنار cpu قرار بده تا از اعمالی که cpu در اجرای اونها مشکل داره و سرعت پایینی داره سرعت ببخشه یعنی به واقع cpu یک نقشی مشابه [/ B]giga thread engine رو میتونه برای کودا کور های انویدیا بازی میکنه اما در مقیاسی بزرگتر و البته بسیار پیچیده تر در APU های نسل اینده.(جدا واسه هرکس جذابه که بفهمه در اینده همکاری کامل و بدون واسطه CPU و GPU میتونه منجر به چه هیولایی بشه)
همونطور که در قسمت های قبل گفتم معماری پردازنده بولدوزر در واقع نمیه راه AMD و در بخش CPU بوده و نمیه بعدی رو GCN در بخش GPU انجام میده تا AMD ضربه شست اصلی خودشو به رقبا نشون بده.
تشریح SIMD در GCN :
در GCN ما درواقع از معماری VLIW صرف و دور میشیم و به چیزی به نام معماری non-vliw SIMD نزدیک میشیم.در اصل هردو به هم شبیه هستن - تعداد زیادی از چیز هارو به صورت موازی RUN میکنن .اما تفاوت اصلی در یک مطلب مهم هست و اون Execution یا اجرای دستورات هست.
در VLIW همه چیز درمورد استخراج دستورالعمل ها و اجرای اون بر روی مقادیر هست که ما به این متد میگیم ILP یا instruction level parallelism که متد اصلی و محبوب amd از گذشته های دور بوده.اما non-VLIW SIMD در اصل در باره ی متد TLP یا thread level parallelism هست که اتفاقا این متد محبوب برند رقیب یعنی Nvidia بوده.(انویدیا بر اساس ترد ها واحد های ارسال رو برای اجرا به هسته ها برنامه ریزی میکرده(هر ترد متشکل از چندین دستورالعمل هست)
قبل از اینکه به طور عمیق وارد تفاوت های vliw و non-vliw simd بریم باید بدونیم vliw برای computing بسیار ضعیفه(همونطور که پیشتر توضیح دادم و برتری قاطع انویدیا رو خدمت دوستان عرض کردم) اما non-vliw اومده تا این مشکل رو حل کنه.
non-vliw چگونه این مشکل رو حل میکنه؟
من به شکل ساده در بالا عدم توانایی GPGPU معماری VLIW رو عرض کردم اما میخوام اینجا ببنیم ایا این مشکل از معماری بد vliw ناشی میشه؟؟
جواب قطعا خیر هست و این مشکل رو ما میتونیم از طریق یک کامپایلر مناسب حل کنیم.در واقع داده هایی که که vliw اجرا میکنه بهتره اولا هم نوع 32 یا 64 از جنس نقاط شناور و یا 24 bit integer باشن و ثانیا غیر وابسته باشن تا simd یا همون SPU بتونه از تمام توانایی خودش استفاده کنه .اگر کامپایلر بتونه این داده هار رو جدا کنه و به ترتیب برای پردازش به SIMD ها بفرسته قدرت معماری VLIW به حدی میشه که به طور مثال یک 5970 با قدرت محاسباتی بیش از 5 tera flops میتونه شخصا یک ابر کامپیوتر تمام عیار باشه.
جالبه بدونید ابر کامپیوتر T در ژاپن به 8.126 Peta flops قدرت رسیده البته بانزدیک به 70.000 پردازنده 8 هسته ای فوجیتسو SPARC64 VIIIfx هر کدام به قدرت 128 gigaFLOPS رسیده.(اگر میتوانستن از تمام قدرت 5970 ها استفاده کنن با 1625 فروند 5970 بجای 70.000 پردازشگر 8 هسته ای کار تمام بود)
اما در GPGPU با در نظر گرفتن بهترین کامپایلر برای سازماندهی دستورالعمل ها باز هم بسیار از دستورات هم نامشابهن و هم وابسته(با در نظر گرفتن این نکته که کامپایلر ها هم به هیچ عنوان عملکرد مطلوبی برای جداسازی هوشمند دستورالعمل ها ندارن اوضاع از این هم بدتر میشه)
تمام اینها موجب این میشه که ما معماری VLIW رو برای پیاده سازی اجرای مطلوب دستورات بسیار پیچیده بخوانیم.در واقع پیچیدگی این موضوع زمانی شدت پیدا میکنه که کامپایلر بسیار خوب هم نمیتونه با همه زبان ها دقیق و مناسب کار کنه.
پی نوشت:
(توضیحات بیشتر باعث پیچیدگی بیش از حد مقاله و سردی دوستان از دنبال کردن ادامه مطلب میشه.اگر دوستان به این بخش که چگونگی پیچیده بودن بیش از حد VLIW برای پیاده سازی COMPUTE هست علاقه نشون دادن میشه به شکلی تخصصی تر روی این موضوع زوم کرد و من در بخشی جدا ادامه بدم)
جایگزینی non-vliw simd به جای vliw :
خوب حالا amd چه چیزی رو با vliw جایگزین میکنه؟میشه اینطور گفت amd پردازنده های برداری معمولی SIMD vector processor رو جایگزین vliw simd میکنه.عناصر cayman به طور مستقیم و با تغییر در GCN منتقل نمیشن.در واقع این sp ها (shader processors) در cayman به وطور کامل با SIMD های GCN تعویض میشوند.
البته این اشتباه نشه SIMD موجود در CAYMAN خود متشکل از چند SP بود اما SIMD موجود در GCN یک 16-wide vector SIMD هست.

نحوه عملکرد اون به این صورته که 1 دستور العمل همراه با 16 تا از عنصر داده data elemnts یک vector SIMD رو در GCN تغذیه میکنن و در یک سیکل ساعت پردازش میشن.مثلا مطابق با wavefront که متشکل از 64 instructions هست این باید 4 سیکل پردازشی رو بگیره تا یک دستور العمل رو در کل wavefronts اجرا کنه.
این واحد vector با یک ثبات 64kb ترکیب شده ور روی هم تشکیل یک SIMD رو در GCN دادن.
گفته شده برخلاف SPs های caymen در simd های جدید این امکان فراهم شده که تعداد مختلف دو داده نا همجنس floating point و integer رو execute کنه.(حال شما خودتون با توجه به توضیحات نسل قبلی ببنید چقدر در compute این GCN قدرتمنده)
البته AMD هنوز اطلاعات پایانی در مورد vector SIMD رو نداده و اما اون چیزی که مشخصه این SIMD های جدید چیزی شبیه واحد های SIMD کایمن هستن با مقیاسی بزرگتر و البته توانایی اجرای داد های نا هم جنس که اگر این عملی بشه من اینده تاریکی رو برای رقیبش NVIDIA در نسل اینده پیشبینی میکنم.البته باید ببنیم در عمل چقدر موفقه اما چیزی که تا الان دستگیر شده قدرت وحشتناک vector SIMD ها در Compute هست.
ونکته قابل تامل دیگه اینه که اگر قراره تمام داده های از جنس fp64 bit هست این simd ها توانایی اینو دارن که با قدرت پردازشی 1/2 داده های fp/32 پردازش کنن.خوبه بدونید در vliw این تقریبا معدل 1/5 32 بیتی بود و این نشون میده در Double pricision قدرت GCN دیوانه کنندست.
حال میریم در ابعاد بزگتر به GCN نگاه کنیم:
Compute UNITE
Many SIMDs Make One Compute Unit
همونطور که از سرتیتر مشخص هست تعداد زیادی Vector SIMD تشکیل یک Compute unit میده.
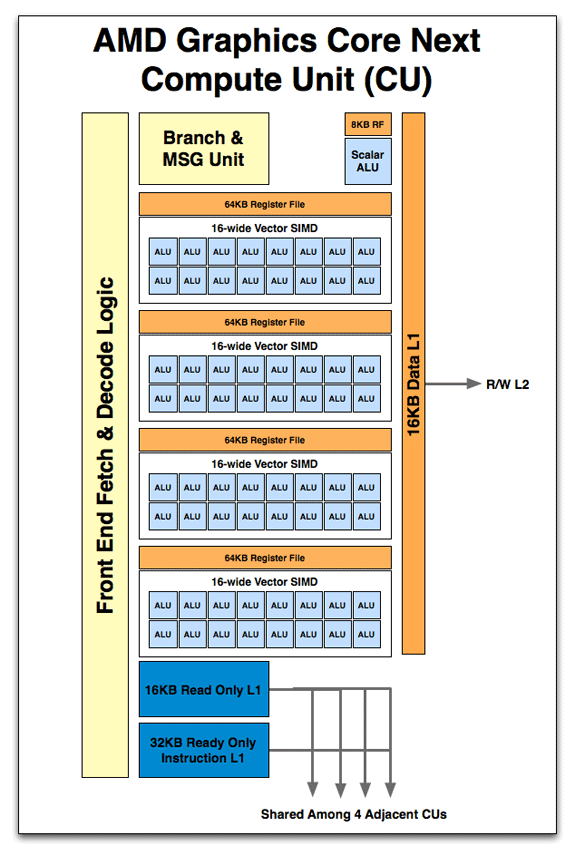
هر CU متشکل از 4 vecor SIMD هست.به این معنا که مشابه Cayman SIMD هر CU در GCN میتونه 4 دستور العمل رو در 1 بار انجام بده .در واقع میشه هر SIMD core در cayman رو معادل یک CU در GCN در نظر گرفت.در Cayman هر simd core شامل 16 فروند streaming processor یا SIMD هست.مثلا در Caymen که 384 عدد streaming processor یا simd هست که در واقع این 384 sp خود در 24 SIMD core قرار گرفتن.
هر CU برای تکمیل 4 ثبات یا Register 64kb که با simd جفت شده یک ثبات 16KB L1 و و دوثبات فقط خواندنی سطح 1 دیگر 16KB و 32KB برای خواندن دستورالعمل ها.درواقع در GCN ثبات سطح 1 کاملا واحد شده و ثبات دیگری برای تکسچر وجود ندارد.واحد Ftech و decod هم برای کار درکنار هر simd برای جذب و دیکدینگ دستورات.و واحد ALU Scaler که بعدا توضیح میدم.
همونطور که گفتم هر CU در واقع مشابه یک SIMD core هست که در نسل گذشته دیده بودم و به شکل زیر هست:

هر یک از sp ها یا straming processor ها در caymen به شکل زیره:
خوب همونطور که میدونیم هر wavefronts در amd شامل 64 دستورالعمل هست که در rack های 16 تایی wavefront قرار دارد(4 عدد ).حال بیایم ببنیم در CU مربوط به GCN و SIMD core مربوط به cayman چطور محاسبه میشه و چه تفاوت هایی باهم دارن(به زبان ساده چون توضیح کاملش پیچیده تر از این حرفاست)
به شکل زیر دقت کنید:
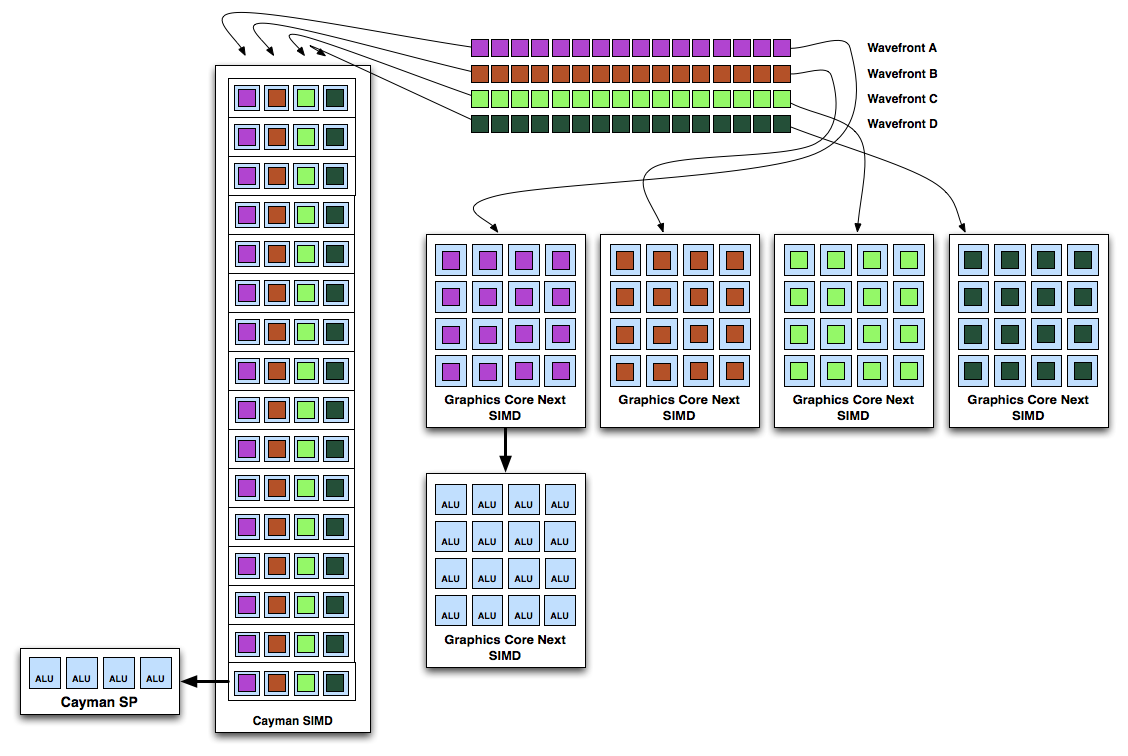
در سمت چپ شکل شما یک SIMD core مربوط به cayman رو میبینید و در سمت راست 4 مربع رو میبینید که مجموعا یک CU یا Compute unit رو تشکیل میدهند.
در بالا سمت راست شما یک wafefronts رو میبینید که شامل 4 عدد wavefront هست که دارای شرایط روبه رو میباشد: VLIW Ideal Scenario: All Non-Dependent Wavefronts
یعنی wavefront ها کاملا به صورت non depend هست و غیر وابسته هست .حال نحوه پردازش در دو معماری:
برای cayman : همونطور که در شکل میبینید wavefront A.B.C.D هرکدام شامل یک دستورالعمل در یک سیکل توسط SIMD core پردازش میشوند.
برای CU ; برای CU هم هریک از SIMD ها یک wavefront را با یک دستورالعمل اجرا میکنن.
این در بهترین حالت ایده ال برای VLIW بود حالا بیاید ببنیم اگر دستورالعملی به بعدی بستگی داشت چه اتفاقی می افتاد:
به تصویر زیر دقت کنید:
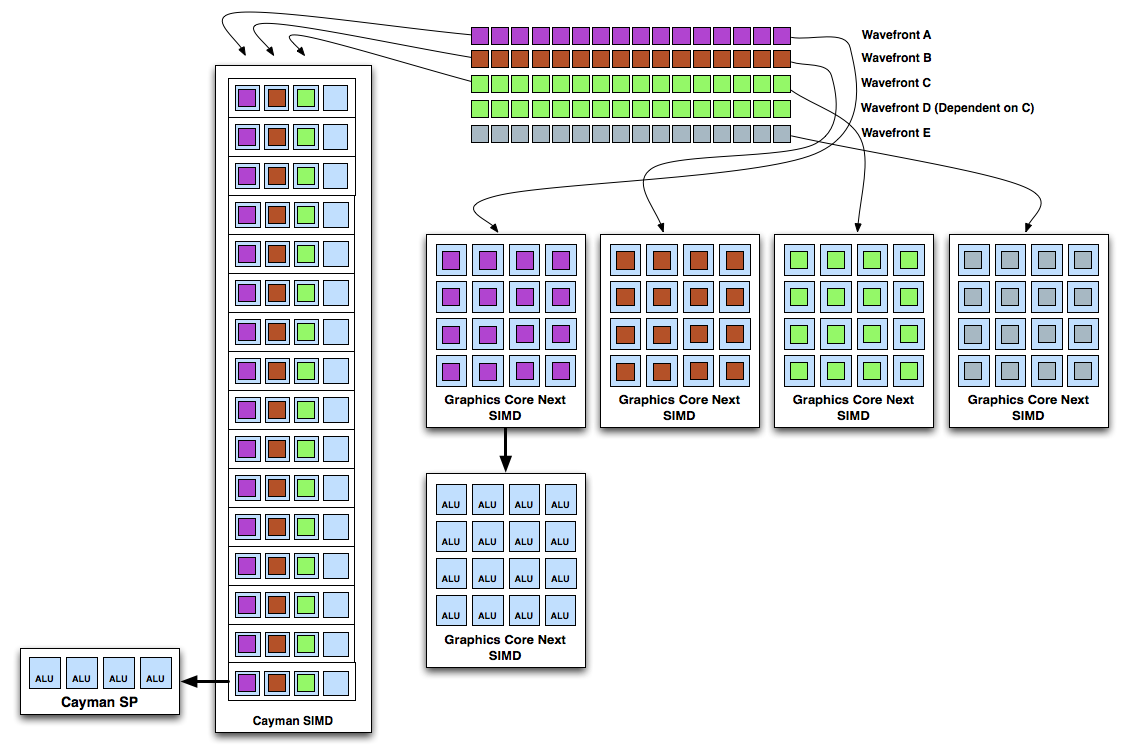
در اینجا ما یک دستورالعمل Wavefront D داریم که برای اجرا نیازمند انجام شدن دستورالعمل Wavefront C هست بنابرای این در Cayman SIMD core یکی از هسته های همه sp ها بی کار میماند.
اما برای CU این طور نیست و زمانبند دینامیک Dynamin schaduler و کامپایلر این دستورالعمل را شناسایی و چون دستور بعدی نیازی به نتیجه D ندارد دستور D را داخل یکی از SIMD های CU میگذارد تا در مرحله بعد D که بستگی به C دارد انجام شود.
امیدوارم سخت نبوده باشه.با کمی دقت متوجه موضوع میشید.
------------------------------
اخرین عضو مهمی که نیاز هست در CU درموردش بحث بشه Scalar ALU هست.
Scalar ALU این واحد جدیدی هست که در GCN به منظور کمک کردن در عملیات هایی که SIMD ها در اونها ناکارامد عمل میکنن.درواقع مهم ترین کار Scaler ALU این هست که داده و عملیات های independent یا مستقل که ممکن است وقت ارزشمند Vector SIMD رو هدر بدن بدن در این واحد اجرا میشوند مثل عملیات های ساده Integer یا کنترل جریان و ..... و scaler unit در هر سیکل ساعت میتونه 1 دستورالعمل رو انجام بده.یعنی اگر یک wavefronts که شامل 64 دستور العمل هست و باید در 4 سیکل ساعت در یک simd انجام بشه در این 4 سیکل ساعت یک scaler unit 4 دستورالعمل رو انجام داده. به طور کلی scaler unit برای non-vectorized بسیار مناسب هست.
و بلاخره GCN GPU:
GCN Graphic processing unit
و تعداد زیادی CU مرحله بالاتر که خود GPU هست رو تشکیل میده شکل زیر رو دقت کنید:
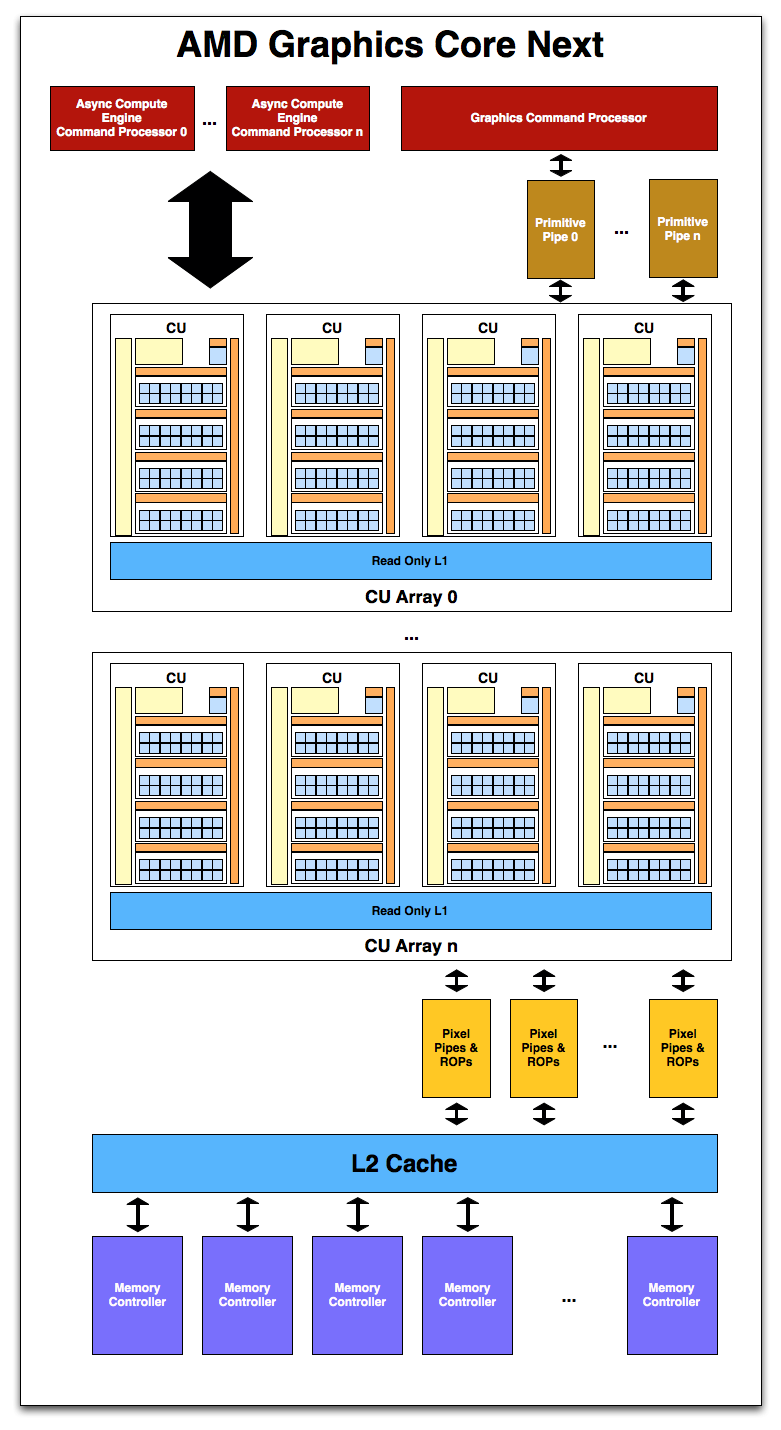
هر GPU در معماری GCN از تعداد زیادی CU ساخته شده.برای مقایسه عرض کردم که هر CAYMAN از 24 عدد SIMD core ساخته شده که هریک از اونها 16 تا sp تشکیل شده بودن و هر sp از 5 عدد alu .
بنابر این اگر به طور مثال Tahiti XT از 50 عدد CU ساخته شده باشد به لحاظ تئوری باید خیلی بیش از چند برابر Cayman توان محاسباتی واقعی و real داشته باشد.(حتی با تعداد برابر هم و تکنولوژی 40nm هم بسیار برتر میبود)
در سطح بالا ما L2 cache رو می بینیم که میتونه به صورت 64KB یا 128KB به ازای هر مموری کنترلر داشته باشه یعنی به طور مثال برای Cayman به ازای هر مموری کنترلر 64kb کش درنظر گرفته شده بود که درمجموع میشد 512KB برای L2 کش(L2 Catch)
و حال واحد جدیدی که برای GCN برای اولین با ظاهر شده و اون Asynchronous Compute Engines هست.
Asynchronous Compute Engines :
این واحد ها به این منظور به خدمت گرفته شدن که به Command processor برای عملیات های مربوط به compute کمک کنند.
هدف اصلی ACEs ها قبول کارها برای ارسال به CU برای پردازش هست.(نقشی شبیه GTE یا Giga thread engine برای انویدیا که شاید عملکرد صحیح و برنامه ریزی صحیح این واحد کارایی نهایی و قدرتمند فرمی رو در محاسبات GPGPU باعث میشد)
از اونجایی که هدف اصلی GCN همون Compute هست ACEs ها باید بتونن با task های مختلف به خوبی کار کنن.amd هنوز اطلاعات زیادی در اینمورد که رابطه بیواسطه بین ACEs و تعداد تسک task هایی که میتونن به صورت همزمان روش کار کنن منتشر نکرده.اما چیزی که مشخصه task ها موارزی متعدد نیاز مند ACE های متعدد هم هست.
یکی از موارد دیگه که درمورد ACE ها باید مشخص بشه اینه:
One effect of having the ACEs is that GCN has a limited ability to execute tasks out of order. As we mentioned previously GCN is an in-order architecture, and the instruction stream on a wavefront cannot be reodered. However the ACEs can prioritize and reprioritize tasks, allowing tasks to be completed in a different order than they’re received. This allows GCN to free up the resources those tasks were using as early as possible rather than having the task consuming resources for an extended period of time in a nearly-finished state. This is not significantly different from how modern in-order CPUs (Atom, ARM A8, etc) handle multi-tasking.
این بود مروری بر معماری نسل اینده GPU های برند AMD .
اگر دوستان سوالی دیدن ازشون خواهش میکنم بپرسن تا من اگر جوابشو نمیدونستم دنبال جوابش برم و چیز های بیشتر یاد بگیرم.هرچند میدونم مقاله سنگینه اما هرچه بیشتر بدونیم بهتره پس لطفا قبل از استفاده نسل اینده GPU های AMD مثل 7970 یکمقدار هم درموردش بدونیم بد نیست.
امیدوارم از مقاله لذت برده باشید.این تقریبا خلاصه شده و ساده شده و با دخل و تصرف منابع دیگه مقاله ANNAND TECH درمورد نسل اینده معماری AMD هست.
همونطور که دیدیم نسل اینده معماری AMD از اونجایی که یک نغییر تماما بنیادی بعد از چندین سال هست.اگر AMD بتونه از پتانسیل این معماری جدید خوب استفاده کنه میتونه ایندرو برای انویدیا و طبق دکترین APU برای اینتل بسیار چالش بر انگیزتر از حال حاظر کنه.
موفق باشید
آخرین ویرایش:

 Google
Google