
بخش 1 :

درود بر دوستان عزیز
اول از همه شرمنده ام که واژه تخصصی رو به کار بردم(تخصص در دستان مهندسین طراح amd/nvidia هست اما چون اینحا قرار نیست از review ها یا مطالبی که همه جا در درسترس هست و همه میتونن ببینن و متوجه بشن صحبتی کنم واژه تخصصی رو به کار بردم-این مقاله شامل بخش هایی هست برای علاقمندان به معماری تراشه ها و افرادی که دوست دارن بدونن این تراشه ها چگونه عمل میکنن و کارایی اونها چیست.
خوب بعد از GCN و Fermi نوبتی هم که باشه نوبت کپلر GK104 هست که برسی بشه.باز هم میگم در این مقاله اصلا قصد ندارم روی مواردی که همه جا چندین چند بار تکرار کردم و یا تکرار شده بحث کنم.همه میدونیم مشخصات کلی کپلر GK104 چی هست و میدونیم این تراشه درواقع Midrange سری کپلر هست که فعلا در رده High End به علت بازدهی بسیار بالا عرضه شده.
در این مقاله بنده سعی میکنم روی تکنولوژی های جدید به کار رفته - برسی تخصصی معماری و تفاوت ها شباهت های کپلر با نسل فرمی و صورت کلی پردازش و مقایسش با رقیب GCN برای برند محترم AMD بپردازم.
قبل از برسی کلی معماری کپلر بیایم ببنیم اصلا قرار بود چه اتفاقی بیفته -نقشه راه ان,دیا کجاست-ایا انودیا کاری خارج از چهارچوب راهبردی اش داشته؟؟؟
بیاید به نقشه راه تصصیح شده nvidia از نسل تسلا تا maxwell که قراره 2014 عرضه بشه نگاهی بندازیم:

طبق این انودیا در نقشه راه خودش پیش بینی کرده بود که با کپلر به بازدهی dp performnce per watte بین 5 تا 6 برابری فرمی خواهد رسید و این برای ماکسول تا 16 برابر فرمی-تسلا خواهد بود. ایا این به نظر شما ممکنه؟؟ ایا انودیا توان چنین کاری رو داشته و میتونه انجام بده؟؟
خوب اگر با هم به برسی معماری کپلر بپردازیم شاید به جواب این سوال برسیم
قبل از هرچیزی قراره در این مقاله چه چیز هایی رو بخونید؟
بنده ابتدا سعی میکنم صورت تفاوت کلی کپلر رو با نسل قبل اون فرمی و حالا اگر فرصتی بود با معماری amd انجام بدم بعد از اون هم به صورت تخصصی به برسی جزئیات معماری و علل کوچک ماندن تراشه با توجه به افزایش بیسابقه هسته ها خدمت دوستان عرض میکنم.
معماری جدید کپلر : تقطیر شده فرمی
اگر نگاهی به GK104 بندازیم حتی Die shot اون رو هم نگاه کنیم متوجه شباهت های بسیار بسیار زیاد اون با نسل قبلی اون فرمی میشیم.در واقع اگر بخوایم منصفانه نگاه کنیم بر خلاف Fermi architecture و GCN تراشه کپلر معماری جدیدی ندارد و نوع جدیدی از فرمی با ویژگی هایی جدید هست.
اگر از دید Multi processor Level (سطح بالا) به تراشه نگاه کنیم به لحاظ عملکرد معماری های فرمی و کپلر بسیار به هم شبیه هستن.اگر با GF100/110 مقایسه کنیم که خوب از اونجایی که روی هسته ها در SM متد ILP عملی نمیشه تفاوت ها بسیار بیشتر هم هستن.بنابراین بهتره اگر در اینده میخوایم از دید ML به تراشه نگاه کنیم بیشتر SM در GF104/114 رو مورد برسی قرار بدیم.
برای اینکه ببنیم تراشه دقیقا به چه صورت عمل میکنه بهتره بیایم از کوچکترین جزء شروع کنیم و پله پله به ساختار تراشه بزرگ برسیم.
درواقع اصل تغییرات در هسته های اجرایی تراشه هستن.
first : an Execution unit Hotclock
یکی از سوالاتی که در این مدت در تمام تاپیک های ایران و خارج از کشور روش زوم شده این هست که چگونه انودیا 3 برابر هسته های gtx580 رو در تراشه ای به کار برده اما فقط 16% به تعداد ترانزیستور های تراشه اضافه شده.این یعنی عملا انگار هیچ اتفاقی نیوفتاده.
این مورد چندین دلیل داره -یکی تعداد بسیار کم SM ها که موجب کاهش تعداد Front end ها و FFU ها شده و من تا به حال چندین بار این رو عرض کردم.
یکی دیگر از ادعاهای انودیا این هست که با از بین بردن hotclock به efficiency بالایی رسیده وهم در حجم تراشه و هم در مصرف برد کرده -برای اینکه ببنیم این حرف ایا عینیت واقعی داره من یک مثال عملی رو خدمت دوستان میارم.
برای درک این سوال باید برگردیم به تئوری ساخت نیمه هادی ها و اینکه چرا تراشه های دارای اجزائ اسنکرون داخلی یا multiple clock (البته در اینجا pumped clock که بعدا عرض میکنم)داخلی که بر خلاف جریان داده (data flow) سطح تراشه چون با فرکانسی متفاوت از کل تراشه عمل میکنن باعث افزایش حجم کلی تراشه در نتیجه استفاده از ترانزیستور بیشتر و نهایتا مصرف بیشتر میشن.
من برای اینکه دوستان درک بهتری از موضوع پیدا کنن یک مسئله تخصصی رو یعنی افزایش حجم یک ALU رو روی یک تراشه ASIC یا FPGA خدمت دوستا نشون میدم.(البته تعریف از خود نباشه فک میکنم اولین بار در دنیا باشه که یک نفر با سنتز مدار به صورت عملی این مورد رو نشون میده (تعریف از خود نباشه : دی )
برای اینکه مسئله رو متوجه بشید من میخوام یک integer ALU رو طراحی کنم که با سنتز برنامه VHDL توسط xilinx ISE یک مدار با ضریب کلاک کل Data flow (به این معنا که ضریب alu با کل تراشه یکی هست) و یک مدار با ضریب کلاک خارج از data flow (در انودیا به صورت pumped clock) چه تاثیری بر حجم کلی این int ALU میگذاره.
خوب من با زبان VHDL یک ALU با مشخصه 8 دستور منطق(logic) و 8 دستور محاسبه (arithmetic) و البته ورودی های 8bit BUS برای ورودی و خروجی و البته یک selector 4bit برای سوئیچ روی دستورات دو بخش منطق و محاسبه ایجاد کردم.
متن برنامه VHDL نیازی نیست خدمت دوستان بدم(در صورت علاقه مندی دوستان بفرمایند من در pm خدمتشون میدم ) و برای شبیه سازی مدار هم از Xilinx ISE v8.2 استفاده شده.
تصویر زیر شماتیک مدار بدون ضریب کلاک اضافی خارج از جریان داده تراشه هست:

تصویر زیر شماتیک همان ALU با ضریب کلاک خارج از Data flow کل تراشه :

اینها سنتز XST شده یک برنامه VHDL برای یک ALU با 16 دستورالعمل هست -تفاوت 2 شماتیک تنها در یک کلاک اضافی برای ALU هست که تقریبا ابعاد تراشرو حداقل 45% اضافه کرده.(در شکل پیداه سازی تا 300% میتونه افزایش داشته باشه اما با بهینه سازی مداری ابعاد تراشه نهایتا 20% اضافه میشه)
اینکه حالا با انجام بهینه سازی ها میشه Pipline Stage هارو بسیار کاهش داد چیز مشخصی هست اما در کل طبق ازمایش بالا به وضوح متوجه شدیم ایجاد یک کلاک خارج از جریان داده تراشه موجب افزایش شدید حجم integrated circuit های مدار و افزایش بی مورد pipline stage ها برای ردگیری کلاک توسعه یافته میشه.
این توضیحات کاملا اضافی و در حد اکادمیک بود و در هیچ ریویو به اون اشاره نشده چون اینها در سطح دانشگاهی و embedded chip designer های این کاره کارشون برسی و شبیه سازی -بهینه سازی تراشه ها هست و اون ادیتور بدبخت شاید به عمرش اسم FPGA/CPLD ها به گوشش نخورده باشه چه برسه به شبیه ساز های تراشه های پیش ساخته بدون handcrafting design : دی
برگردیم به بحثمون و اینکه انودیا چگونه بدون افزایش زیاد ترانزیستور این همه هسته به sm ها اضافه کرده.
یکی از تئوری ها و مسائل اصلی طراحی های انودیا از سری G80 یا GT200 با اسم رمز تراشه تسلا تا همین فرمی استفاده از واحد های اجرایی در فرکانسی بسیار بالاتر از کل تراشه با یک ضریب خاص بود.انودیا پیش تر اسم اون رو Shader Clock گذاشته بود و واحد های اجرایی execution Unite ها با ضریب ثابتی مثلا در فرمی 2x یا در نسل های پیشتر به ترتیب زیادتر تا 2.5x نسبت به فرکانس کل تراشه بیشتر بود.درواقع این سیستم که با نام double pumped شناخته میشود برای یک Execution unit به منظور 2 برابر کردن فرکانس هسته های اجرایی توسط اینتل از زمان NetBurst architecture شروع (همون معماری که در هسته های pentium 4 بکار رفت) و توسط انودیا از زمان نسل تسلا تا همین فرمی ادامه داشته.
حال در کپلر چه اتفاقی افتاده !!!
طبق نقشه راه مهندسین Nvidia معماری نسل اینده باید راندمان بی نهایت بالایی داشته باشه-طوری که طبق نقشه راه انودیا تا 5 الی 6 برابر نسل گذشته کارایی نسبت به توان برای معماری کپلر در نظر گرفته بشه.
طبق بیان NVIDIA's VP of GPU Engineering جناب اقای Jonah Alben ما اینو ساختیم پس بزارید بهبودش هم بدیم.

در این معماری به جای 2 برابر کردن هسته های اجرایی برای بازدهی بالاتر اومدن هسته های اجرایی رو چند برابر به نفع راندمان بالاتر کردن بنا بر این کل warp ها (در review فرمی که خیلی پیش تر ها داده بودم که متاسفانه بنا به دلایلی که البته خودم مقصر بودم به نام شخص دیگه ای ثبت شده توضیحات کامل warp هارو خدمت دوستان دادم)
باسیستم زمان بندی جدید در کل هسته ها issue و پخش میشن و بدون انجام کار با سرعت 2برابر front End همگام با اون منتظر روال بعدی warp ها میشن به این صورت تراشه به بازدهی بالاتر میرسه.
تصویر زیر قیاس کلی و بهبود های Elimination hotclock هست:

توضیحات:
1 : هر 2 هسته کپلر با pipline instruction مشابه بدون 2x clock تنها 1.8 برابر 1 هسته در فرمی رو داره(عملا هر هسته کپلر حدود 10% کوچکتر از هر هسته در فرمی هست)
توضیح: قطعا 2xclock موجب افزایش روال instruction pipline ها میشه و همین موجب افزایش 10% هر fermi cuda core نسبت به kepler cuda core میشه(در اثبات سنتز مدار alu بنده هم به نتیجه 45% افزایش رسیدیم که البته بدون بهینه سازی مدار بود)
2 : هر 2 هسته موجود در کپلر به اندازه 90% توان مصرفی 1 هسته در فرمی مصرف داره بنابراین عملا این حرکت انودیا مهر ختمی بود برا shaderclock ها.
3 : وقتیکه ما حرف سرعت کلاک رو هم بیاریم وسط باز هم اختلاف عمیق تر میشه و اینجا 2 هسته کپلر 50% 1 هسته انودیا در کلاک مشابه مصرف دارن.
خوب این تازه گوشه ای از اعمال تغییرات مهندسین انودیا بود - حرکت بعدی اعمال تغییرات در سلسله روال زمان بندی بخش front End هست که در بخش بعد خدمت دوستان صحبت میکنم
در این بخش متوجه میشیم که چرا افزایش 3 برابری هسته ها لزوما به صورت خطی موجب افزایش 3 برابری کارایی نشده.
در علوم کامپیوتری و معماری تراشه ها و میکروپروسسور ها عموما از دو طرف میشه به تراشه ها نگاه کرد :
الف:بخش کنترلی تراشه
ب: بخش اجرایی تراشه
توضیح الف: بخش کنترلی و اعمال داده یک هسته مستقل که میتونیم اون رو Front End یا حتی در موارد ساده تر Control Unite بنامیم - بخشی هست که به طور کلی میتونیم مراحل زیر رو برای اون متصور بشیم:
1: ابتداوظیفه واکشی ترد ها (fetch)
2: برداشت اونها از کاشه دستورالعمل(inst catch) و ترجمه دستوزالعمل (instruction decoding)
3: صف بندی و زمان بندی ارجاع دستورالعمل ها (schaduling)
4: ارجاع دستورات زمان بندی شده به واحد اجرایی (issue)
توضیح ب: بخش اجرایی در واقع وضیفه excute دستورات ارسالی از طرف Front End رو داره و بخش اجرایی کارامد است که به بهترین نحو وظایف ارسالی از طرف CU رو به انجام برسونه.
تمامی تراشه ها و پردازنده ها از منطق ساده بالا پشتیبانی میکنن (هرچند در بعضی منطق طراحی تراشه ها قسمت هایی حذف و یا قسمت هایی اضافه میشه اما روال کار معمولا یکی هست)درواقع اصل اساسی بالا معتبر هست و در جزئیات تفاوت ها ایجاد میشود - مثل تکنولوژی های اینتل در پردازنده های خود برای به حداکثر رسوندن IPC که اینجا مجالی برای توضیح اونها نیست و ربطی هم به این تاپیک نداره (اگر استقبال بشه بعدا در اون مورد هم صحبت میکنیم).
مهندسین طراح پردازشگر ها معمولا چندین راه برای اعمال متد پردازشی بالا رو دارن و این متد ها رو شاید بشناسید .در این مقاله مجالی برای توضیح انواع اونها نیست من فقط به منطق Nvidia و نسل پیشین و مقایسه اون با کپلر میپردازم.
--------------------------------------
در منطق زمان بندی دستورالعمل ها برای اجرا در تراشه های قدیم و جدید ( مراحل 2 و3 ) مهندسین طراح همیشه 2 راه رو پیش روی خودشون داشتن
static scheduling
در این متد زمان بندی دستورات و طبقه بندی و اسال اونها طبق یک جدول از پیش تایین شده instruction info که توسط نرمافزار software به تراشه همراه با اطلاعات operand ها و instruction ها هست ارسال میشه و عملا front end تنها وظیفه ورپ سازی و ارسال اونها رو به execution units ها داره (توضیح دقیق ترشو از دید ML در ادامه خدمت دوستان میدم):
1 : در این حالت تراشه بشدت شکل intensively compiler به خودش میگیره و درواقع توان autonomously processing خودش رو بشدت از دست میده و به برنامه نویسان و کارایی بهینگی استفاده از پردازنده برای زمان بندی اونها محتاج میشه.
2: کار برنامه نویسان و درایور سازان برای بهینگی درایور زمانبند توسط پردازنده برای اون تراشه بسیار بسیار مشکل میشه چون باید بهترین حالت بهینگی نرم افزار رو برای تراشه ایجاد کنن که عملا با حجم وسیع محصولات در PC عملا این کار بی نهایت دشوار تر هم میشه.(تمام اینها به منظور زمان بندی صحیح و بهینه توسط درایور هست)
3:درصورت بهینگی ارجاع و زمانبندی دستورالعمل ها قدرت تراشه میتونه به صورت خطی افزایش پیدا کنه(توان تراشه در صورت بهینگی ارجاع دستورات به شکل غیرقابل تصوری بالا میره چیزی که در کنسول های بازی میبینیم)
4: این سیستم موجب کاهش پیچیدگی Front End میشه در نتیجه در die size اختصاصی واحد کنترل میتونن صرفه جویی کنن.
5: کاهش autonomously processing به معنای از دست دادن حدی قدرت محاسباتی computing capibility هست(که البته در گیمینگ تاثیری نداره).چون تراشه عملا به طیف وسیع و متفاوت دستورالعمل ها نمیتونه واکنش مناسب بده و نیازی به برنامه ریزی مستقیم تراشه برای کارکرد منسب به ازای هر دستور متغیر هست و این برای داده های محاسباتی پیشچیده اصلا مناسب نیست.
HardWare scheduling
در این متد بخش Front End طوری طراحی میشه که حدالمکان بتونه به صورت مسقل تمامی وظایف زمانبندی و چک instruction dependency و ...رو به صورت خودمختار انجام بده ( هر چند اصل کار رو پردازنده از طریق اعمال درایور انجام میده و توضیحات تکمیلی در ادامه متن خدمت دوستان میدم) :
بیاید به مزایا و معایب این سیستم نگاهی کنیم:
1: در این حالت تراشه خودمختار تر از SW scheduling هست
2: برنامه نویسان کار راحت تری برای بهنگی نرم افزار ها روی تراشه دارن چون عمده کار رو بخش Front End تراشه به عهده داره.سرعت بهینگی نرمافزار ها برای تراشه بهبود زیادی نسبت به متد قبلی داره.
3: چون بخش Front End خود وظیفه چک وابتگی دستورالعمل ها و ایجاد جدول زمانبدی دستورات رو داره عملا Front End به کلاک های بیشتری برای ایجاد ریسمان (warp) های مناسب برای تغذیه Execution unite ها نسبت به مدل قبلی داره.یعنی در صورت بهینگی دستورات برای حالت قبل عملکرد تراشه با SW method بسیار چشمگیرتر خواهد بود.
4:این سیستم موجب افزایش پیچیدگی و مدار های داخلی برای CU هست که بتونه به صورت خودمختار (Autonomously) دستورات رو dependency checking و scheduling کند.
5: افزایش autonomously processing به معنای بدست اوردن حدی قدرت محاسباتی Compute در تراشه هست.چون تراشه عملا به طیف وسیع و متفاوت دستورالعمل ها میتونه واکنش مناسب بده و نیازی به برنامه ریزی نداشته باشه.
این بود شکل کلی این روال ها که قاعدتا عینن در GPU ها اجرا نیمشه اما شباهت هایی داره که بعدا خدمت دوستان عرض میشه.
در کپلر چه اتفاقی افتاده؟خوب اگر بخوایم منصافنه بگیم
خوب پیش از هرچیزی باید بگیم مهندسین انودیا در کپلر تصمیم گرفتن متد SW scheduling رو پیاده سازی کنن.برای فهم بیشتر به تصویر زیر دقت کنید:
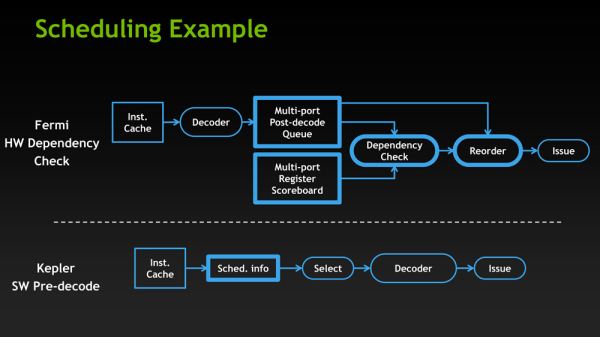
در تصویر بالا شما شاهد نحوه قرار گیری بلاک و سیستم زمانبند در فرمی و کپلر هستیداگر بخوایم برای توضیح از نسل قبل فرمی شروع کنیم باید بگیم سیستم HW scheduling تراشه ای مثل GF114 در بخش FRONT End نه تنها قادر به انجام کار های پایه ای زمانبدی مثل scoreboarding (منظور از scoreboarding نگاهداری ریسمان warp هایی است که روی مموری در انتظار دسترسی به واحد های اجرایی هستن یا باقی عملیات هایی که تاخیر زیادی دارن) و یا انتخاب و برداشت warp ها از بخش pool ریسمان ها برای اجرا بود بلکه علاوه بر اینها Front End فرمی مسئول زمانبندی خود دستورالعمل های موجود در ریسمان ها هم بود.
این مورد در فرمی عملا موجب میشد که تراشه قادر به انجام اعمال محاسباتی با حد تغییر زیاد دستورالعمل ها به خاطر پیچیدگی FE اون باشه.پیچیدگی Front End برای تراشه ای که تعداد کمی واحد زمانبند در تراشه خود داراست عامل مهمی محسوب نمیشه .
اما این پیچیدگی که موجب پایین امدن power and area efficiency میشود برای تراشه ای که 32 واحد زمانبند در سطح تراشه خود دارا هست عملا موجب افزایش شدید سطح تراشه وپایین امدن بازدهی اون میشه و این برای کپلر GK104 غیر قابل قبول هست.
به همین علت براورد مهندسین nVIDIA برای کپلر استفاده از همین static scheduling هست تا به power and area efficiency بالایی برای تراشه برسن.
برای توضیح و فهم بیشتر و اینکه این مورد در GPU ها چگونه هست متن زیر رو با دقت بخونید:
به طور سنتی (در نسل فرمی الاخصوص) پردازنده با توجه به دستورات درایور شروع به ساخت یک روال ثابت زمانبندی static scheduling میکنه و سپس اون ها رو به واحد های زمانبندی سخت افزاری GPU میفرسته که این باعث افزایش پیچیدگی هم بخش Hardwrae و هم software میشود(هرچند بخش software نسبت به حالت تماما نرمافزاری کار راحت تری رو پیش رو داره).به طور کلی Hardware instruction scheduling به پردازنده اجازه میده به بهترین روش ممکن و با بالاترین بازدهی که اجازه داده میشه به صورت real time دستورات رو زمانبندی کنه بدون در نظر گرفتن به روال موکد دستور دهی خودش دستورات رو زمان بندی میکنه.این به نوبه خودموجب افزایش بازدهی پردازنده میشه.
(معذرت میخوام اگر کمی مشکل هست بحث بالا اگر سوالی بود در ادامه تاپیک خوشحال میشم بپرسید)
خوب طبق صحبت های بالا Hardware scheduling بسیار عالی هم هست-اما تحقیقات اخیر محققین انودیا چیز دیگه ای رو نشون داده:در ادامه به این میپردازیم:
تحقیقات و شبیه سازی های معماری اخیر انودیا نشون داده که HW scheduling میزان منصفانه ای از مصرف رو در ازای فواید ناچیز در تراشه به ارمغان میاره -به طور خاص چون Pipeline math های کپلر دارای تاخیر های ثابت هستن(نسبت به نسل قبل execution unit ها در نصف فرکانس کار میکنن پس عملا این تاخیر موجهه) بنابر این وجود HW Scheduling درون سیستم warp ها(ریسمان ها) عملا زاید هست چون کامپایلر تراشه میدونه زمان تاخیر صدور هر دستورالعمل محاسباتی چقدر هست.
بنابراین انودیا تصمیم گرفت به جای زمانبند های پیچیده سخت افزاری complex scheduler اونهارو باز مانبند های ساده ای که هنوز از scoreboarding و دیگر متد های زمانبدی داخلی ورپ ها استفاده میکند جایگزین کند.به بیان دیگر زمانبندی ورپ ها توسط کامپایلر یعنی برگشتن انودیا به سیستم قدیم static scheduling .
سیستم sw scheduling در برابر hw scheduling با تمام ویژگی های مفیدش عملا باعث میشه تراشه در مقابله با complex compute applications دچار مشکل باشه(در بالا خدمت دوستان عرض کردم) به همین علت بود که در فرمی با استفاده از اون سیستم انودیا تراشه هایی رو مناسب با COMPUTE و GPGPU طراحی کرده بود و AMD هم با معماری GCN و استفاده از HW scheduling عملا به دنبال راه قدیم انودیا بود.
اما انودیا فعلا تصمیم گرفته برای هر بخش تراشه هایی متناسب با اون زمینه تولید کنه و این یعنی برای gpgu هم انودیا برنامه هایی روداره.
سیستم SW scheduling در صورت صحت عملکر کامپایلر میتونه انقلابی رو در استفاده از قدرت تراشه ایجاد کنه-تنها مشکل این هست که تاثیر درایور ها بر روی قدرت تراشه رو بسیار چشمگیر تر از گذشته ها میکنه.
همونطور که میدونید کپلر GK104 تا 3 برابر هسته های GTX580 رو داره اما عملا قدرت هسته ها به صورت خطی افزایش پیدا نکردن-اما این پتانسیل وجود داره که در صورت بهینگی استفاده از هسته ها این تراشه قدرت خودش رو نشون بده.

توضیحات تفاوت سیستم هایی که ساماریتن روی اونها اجرا شده رو در تصویر میبینید-کلا تراشه هایی که سیستم sw Scheduling أارن برای کنسول ها بسیار مناسب هستن چون میتونن بازی رو برای یک محصول و تراشه بسیار بهینه سازی کنن هرچند در سیستم HW scheduling هم امکان پذیره و حتی بهتر اما کمبود Effeciency این سیستم ها عملا اجازه نمیده اونها در این قسمت زیاد موفق باشن.
البته دموی ساماریتن روی کپلر با تکنیک FXAA اجرا شده بود که باعث میشد Memmory tax برنامه بسیار کاهش پیدا کنه و 2GB رم GTX680 برای این دمو کافی به نظر برسه.
برگردیم سر ادامه بحثمون:
حال بهتره از دید مالتی پروسسور به تراشه نگاه کنیم و اون رو با GF114 مقایسه کنیم:
به تصویر زیر که شمایی از یک sm در GF104/114 هست نگاهی بیندازید:
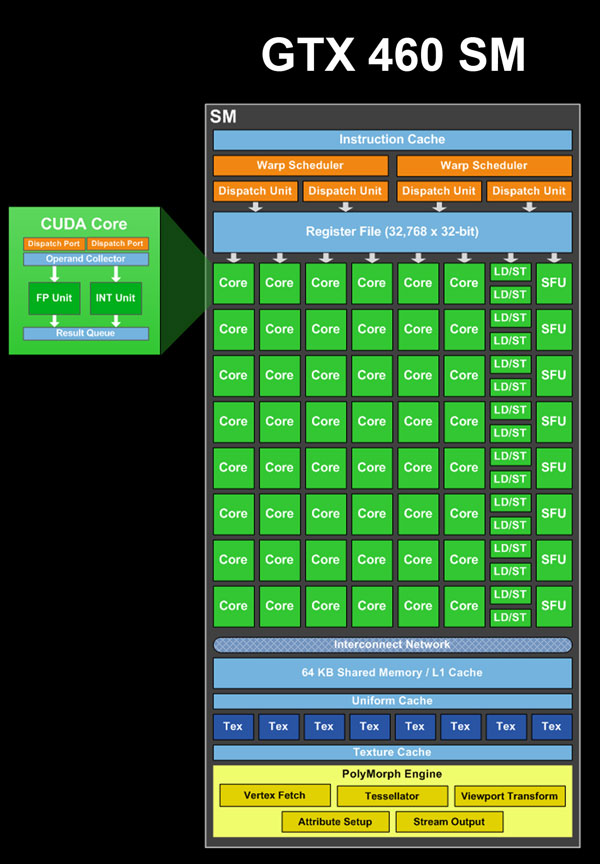
خوب همونطور که در بالا هم عرض کردم در سیستم SM موجود در GF104 با توجه به اینکه متد ILP توسط HW scheduling چک میشه برخلاف GK104 که از طریق نرم افزار و کامپایلر با جدول ثابت هست بنابر این نمیتونیم بخش Front End اونو مستقیما به gk14 تامیم بدیم اما باز هم مناسب تر از GF100 هست.
در این SM منابع عملیاتی اجرایی تراشه به 3 گروه 16 تایی کودا که فقط یکی از اونها قابلیت اجرای دستورات Fp64 رو داره تقسیم میشه و گرو های تابعی دیگر رو هم که مجموعا 7 گرو هستن میتونید مشاهده کنید:
GF104/GF114 SM Functional Units
16 CUDA cores (#1)i
16 CUDA cores (#2)i
16 CUDA cores, FP64 capable (#3)i
16 Load/Store Units
16 Interpolation SFUs (not on NVIDIA's diagrams)i
8 Special Function SFUs
8 Texture Units
خوب کارایی بخش های اون رو پیشتر در مقاله فرمی خدمت دوستان توضیحات مفصل دادم(دوستانی که اصل مقاله فرمی رو بدون اضافات و مهملاتی..... مثل به باور من یا فوق تخصصی و ........ که از شاهکار های اون دوست گرامیمون هست و البته عکس های با رزولوشن بالا بدون گذاشتن Vfsdf در گوشه عکس ها میخوان بفرمایند در Pm خدمتشون فایل word اصلی رو بدم)
حال به شمایی از یک smx در GK104 بهتره نگاهی بندازیم:
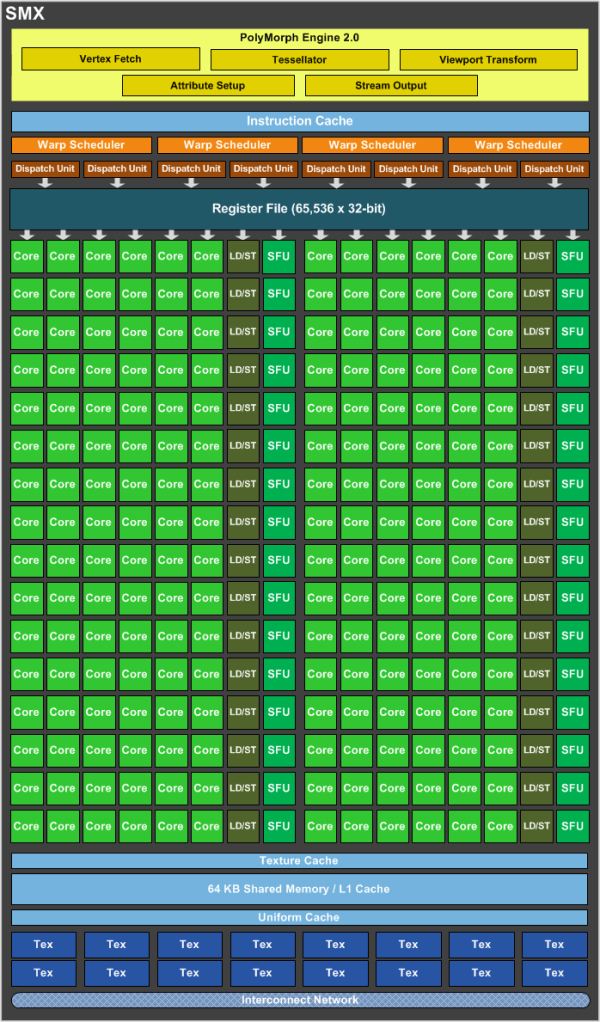
برخلاف نسل پیش که تنها 7 بخش اجرایی عملیاتی تابعی functional units وجود داشت در smx کپلر ما شاهد 15 بخش functional units هستیم به این معنا که زمانبند ریسمان ها warp cheduler ها میتونن 15 بخش functional رو فراخوانی کنن.
عملا 2 برابر شده منابع اجرایی و تابعی در کپلر GK104 نسبت به نسل قبلی GF104/114 به انودیا اجازه میده shaderclock رو که فرکانس منابع اجرایی رو 2 برابر میکرد خیلی راحت و بدون هیچ مشکلی حذف کنه و اصلا احساس کمبود منابع عملیتاری ور هم نکنه.
در زیر به ترتیب واحد های functional units رو میبینید:
GK104 SMX Functional Units
32 CUDA cores (#1)i
32 CUDA cores (#2)i
32 CUDA cores (#3)i
32 CUDA cores (#4)i
32 CUDA cores (#5)i
32 CUDA cores (#6)i
16 Load/Store Units (#1)i
16 Load/Store Units (#2)i
16 Interpolation SFUs (#1)i
16 Interpolation SFUs (#2)i
16 Special Function SFUs (#1)i
16 Special Function SFUs (#2)i
8 Texture Units (#1)i
8 Texture Units (#2)i
8 CUDA FP64 cores
اگر به SMX دقت کنید 4 زمانبند ریسمان warp schedulers وجود داره که میتونن در هر سیکل ساعت 2 دستورالعمل رو در صورت احراز شرایط ILP (منظور Instruction level parallelismهست که در اون وابستگی دستورات بر طبق اصل super scaler ای چک میشه که از وظایف HW/SW dependency cheking هست) رو فراخوانی کنه یعنی اگر تمام شرایط ILP صادق باشه هر 4 زمانبند میتونن 8دستورالعمل رو بز I-set catch برای ریسمان سازی فراخوانی کنن و به توابع اجرایی ارسال کنن
از طرف دیگه تعداد texture unite ها دقیق 2 برابر شده و این برای کل تراشه از 64 در نسل قبل به 128 در نسل فعلی رسیده که عملا خیلی بیش از ظرفیت FFU هایی است که باید روال Graphic pipline رو در تراشه اعمال کنن.(منظور از کم بودن ffu کم بودن تعدادsm هاست و هر ffu شامل همون poly morph انجین میشه که به ازای هر sm فقط 1 پولیمورف انجین وجود داره.
به همین علت انودیا سیستم جدیدی رو برای تکسچر ها برنامه ریزی کرده به نام Bindless Textures تا بتونه نهایت توان تغذیه تکسپر هارو داشته باشه(برای 2 برابر واحد تکسچر نسبت به نسل قبل).درک چگونگی کار کرد این سیستم به تصویر زیر دقت کنید:

در گذشته و نسل های پیش از کپلر هر sm میتونست برابر 128 عدد تکسچر رو هزمان برای انجام اعمال graphic pipline فراهم کنه اما با سیستم جدید تراشه میتونه عملا در طول shader code ها هر مقدار تکسچر(بالغ بر 1 میلیون تکسچر) رو همزمان فراهم کنه و این به قول bsn یکی از کلیدی ترین دلایلی بود که دموی عظیم samaritan تنها بر روی یک کارت تونست اجرا بشه.
البته AMD هم از سیستم جدید به نام Partially Resident Textures, i.e. MegaTexturing technology با رهبری JOHN CARMACK کبیر برای موتور های OpenGL خودش بهینه بوده پرده برداری کرد که به نظر Bsn در جای خودش محترم هست اما در برابر سیستم جدید انودیا چون ورای محدودیت هایOpenGL limited هست سیستم کارامدتری میاد.(هر کدوم از اینها جای بحث زیادی دارن و در حوصله این مقاله نمیگنجه)
خوب حل بیاید کل تراشه هارو با هم مقایسه کنیم:
شمای کلی GF104/114 که در زیر میبینید:

شمای کلی GK104 که در زیر میبینید:

خوب مشخصه های تراشه واضح هست و من نیازی نمیبینم که اون هارو چندین بار تکرار کنم در شکل زیر میتونید ببنید:

تنها نکات قابل عرض در سطح SM ها وجود نسل 2 FFU های انودیا برای DX11 یعنی Plymorph Engine 2 هست که انودیا این بخش رو برای تراشه های نسل جدید از نوع بهینه سازی کرده.
در شکل زیر میتونید شمای polymorph Engine 2 رو ببنید:

انودیا در واقع با PE 2 سعی کرده نیاز اساسی 3-4 برابر شدن هسته های هر SM رو برای پوشش روال Graphic pipline پوشش بده - این بخش از تراشه هنوز 5 مرحله graphic pipline یعنی از مرحله Vertex Fetch تا مرحله Stream Output که هر یک از این مراحل توسط هسته های پردازشی SMX پردازش و توسط این Stage ها مرتبط میشن.
درواقع تفاوت اصلی این نسل از polymorph enginde ها با نسل گذشته ازفیش شدید بازدهی جریان داده data stream efficiency هست . به بیا دیگر نرخ مقادیر اولیه throughput داده ها (primitive rates) در نسل جدید بالغ بر 2 برابر نسل پیش هست که اجازه میده data through put به درون هسته ها تا 4 برابر نسل پیش افزایش پیدا کنه و عملا کارایی تسلیشن تنها بهبتونه به 4 برابر نسل پیش(فرمی) برسه.
more internal connection =more data transfer
انودیا با عرضه کپلر ادعا کرده که بالاترین نرخ تبادل داده رو در تراشه تا به حال به نام خودش ثبت کرده:

بدون کنترلر مموری کارامد هیچ تراشه ای موفق نیست -این مهم نیست که تراشه شما چقدر سریع هست - مهم اینه که هسته های اجرایی شما گرسنه نمانند-برخلاف پردازنده ها memmory controller یکی از مهمترین بخش های GPU محسوب میشه - بدون سرعت کافی اون Catch hirarchy نمیتونه روال خودش رو همگام با سرعت بالای هسته ها پیش ببره بنا بر این هسته ها دچار معضل گرسنگی میشن.
در واقع یکی از علل شکست Intel Larrabee و ATI R600 همین ناکارامد بودن memmory controller effeciency بود.
چگونه انودیا به این رقم دست پیدا کرده ؟؟
به تصویر زیر دقت کنید:

برای انجام مناسب سلسله روال دسترسی هسته ها به مموری-انودیا با ایجاد cache hierarchy موثر و سطح عظیم internal memmory connections در سطح تراشه از زمان فرمی و ارتقائ اون در کپلر عملا به بالاترین حد راندمان عملکرد حافظه تا به اکننون رسیده.
خوبه بدونید کارتی مثل gtx680 در 1.50 GHz QDR عمل میکنه و در مقام مقایسه تراشه 384bit ای high end AMD یعنی Tahiti در 1.375 GHz QDR عمل میکنه که البته رقم بدی نیست (حدود5500 mhz effective هست)
هسته های متعدد و بسیار زیاد نسل کپلر نیاز به تغذیه بالایی دارن و عملا این میزان پهنای باند هسته ای اجرایی رو دچار معضل گرسنگی نمیکنه.
--------------------
این بود مروری بر معماری نسل نوین کپلر GK104 انودیا که امیدوارم کافی بوده باشه- سعی کردم مقاله جلوتر از اکثر ریوی های خارجی و کامل تر و اساسا روی اصل موضوعات تخصصی باشه
در بخش بعد به ویژگی های جدید معرفی شده همزمان با کپلر مثل Adjusment Vsync و Txaa و ..... میپردازم تا ببنیم اونها چگونه به افزایش قابلیت های این تراشه کمک میکنن.
اگر سوالی بود حتما پرسیده بشه چون این مقاله تنها جنبه تخصصی و برسی معماری تراشه رو داشت و قصدم از این ریویو برسی بنچمارک ها نبود.
امیدوارم مفید بوده باشه.
منابع :
bsn
annadtech
hardwarecanucks
hexus
در بخش شبیه سازی و اکثر توضیحات تکنیکی هم بنده حقیر
موفق باشید
درود بر دوستان عزیز
اول از همه شرمنده ام که واژه تخصصی رو به کار بردم(تخصص در دستان مهندسین طراح amd/nvidia هست اما چون اینحا قرار نیست از review ها یا مطالبی که همه جا در درسترس هست و همه میتونن ببینن و متوجه بشن صحبتی کنم واژه تخصصی رو به کار بردم-این مقاله شامل بخش هایی هست برای علاقمندان به معماری تراشه ها و افرادی که دوست دارن بدونن این تراشه ها چگونه عمل میکنن و کارایی اونها چیست.
خوب بعد از GCN و Fermi نوبتی هم که باشه نوبت کپلر GK104 هست که برسی بشه.باز هم میگم در این مقاله اصلا قصد ندارم روی مواردی که همه جا چندین چند بار تکرار کردم و یا تکرار شده بحث کنم.همه میدونیم مشخصات کلی کپلر GK104 چی هست و میدونیم این تراشه درواقع Midrange سری کپلر هست که فعلا در رده High End به علت بازدهی بسیار بالا عرضه شده.
در این مقاله بنده سعی میکنم روی تکنولوژی های جدید به کار رفته - برسی تخصصی معماری و تفاوت ها شباهت های کپلر با نسل فرمی و صورت کلی پردازش و مقایسش با رقیب GCN برای برند محترم AMD بپردازم.
قبل از برسی کلی معماری کپلر بیایم ببنیم اصلا قرار بود چه اتفاقی بیفته -نقشه راه ان,دیا کجاست-ایا انودیا کاری خارج از چهارچوب راهبردی اش داشته؟؟؟
بیاید به نقشه راه تصصیح شده nvidia از نسل تسلا تا maxwell که قراره 2014 عرضه بشه نگاهی بندازیم:
طبق این انودیا در نقشه راه خودش پیش بینی کرده بود که با کپلر به بازدهی dp performnce per watte بین 5 تا 6 برابری فرمی خواهد رسید و این برای ماکسول تا 16 برابر فرمی-تسلا خواهد بود. ایا این به نظر شما ممکنه؟؟ ایا انودیا توان چنین کاری رو داشته و میتونه انجام بده؟؟
خوب اگر با هم به برسی معماری کپلر بپردازیم شاید به جواب این سوال برسیم
برسی معماری کپلر

قبل از هرچیزی قراره در این مقاله چه چیز هایی رو بخونید؟
بنده ابتدا سعی میکنم صورت تفاوت کلی کپلر رو با نسل قبل اون فرمی و حالا اگر فرصتی بود با معماری amd انجام بدم بعد از اون هم به صورت تخصصی به برسی جزئیات معماری و علل کوچک ماندن تراشه با توجه به افزایش بیسابقه هسته ها خدمت دوستان عرض میکنم.
معماری جدید کپلر : تقطیر شده فرمی
اگر نگاهی به GK104 بندازیم حتی Die shot اون رو هم نگاه کنیم متوجه شباهت های بسیار بسیار زیاد اون با نسل قبلی اون فرمی میشیم.در واقع اگر بخوایم منصفانه نگاه کنیم بر خلاف Fermi architecture و GCN تراشه کپلر معماری جدیدی ندارد و نوع جدیدی از فرمی با ویژگی هایی جدید هست.
اگر از دید Multi processor Level (سطح بالا) به تراشه نگاه کنیم به لحاظ عملکرد معماری های فرمی و کپلر بسیار به هم شبیه هستن.اگر با GF100/110 مقایسه کنیم که خوب از اونجایی که روی هسته ها در SM متد ILP عملی نمیشه تفاوت ها بسیار بیشتر هم هستن.بنابراین بهتره اگر در اینده میخوایم از دید ML به تراشه نگاه کنیم بیشتر SM در GF104/114 رو مورد برسی قرار بدیم.
برای اینکه ببنیم تراشه دقیقا به چه صورت عمل میکنه بهتره بیایم از کوچکترین جزء شروع کنیم و پله پله به ساختار تراشه بزرگ برسیم.
درواقع اصل تغییرات در هسته های اجرایی تراشه هستن.
Building A kepler GK104
first : an Execution unit Hotclock
یکی از سوالاتی که در این مدت در تمام تاپیک های ایران و خارج از کشور روش زوم شده این هست که چگونه انودیا 3 برابر هسته های gtx580 رو در تراشه ای به کار برده اما فقط 16% به تعداد ترانزیستور های تراشه اضافه شده.این یعنی عملا انگار هیچ اتفاقی نیوفتاده.
این مورد چندین دلیل داره -یکی تعداد بسیار کم SM ها که موجب کاهش تعداد Front end ها و FFU ها شده و من تا به حال چندین بار این رو عرض کردم.
یکی دیگر از ادعاهای انودیا این هست که با از بین بردن hotclock به efficiency بالایی رسیده وهم در حجم تراشه و هم در مصرف برد کرده -برای اینکه ببنیم این حرف ایا عینیت واقعی داره من یک مثال عملی رو خدمت دوستان میارم.
برای درک این سوال باید برگردیم به تئوری ساخت نیمه هادی ها و اینکه چرا تراشه های دارای اجزائ اسنکرون داخلی یا multiple clock (البته در اینجا pumped clock که بعدا عرض میکنم)داخلی که بر خلاف جریان داده (data flow) سطح تراشه چون با فرکانسی متفاوت از کل تراشه عمل میکنن باعث افزایش حجم کلی تراشه در نتیجه استفاده از ترانزیستور بیشتر و نهایتا مصرف بیشتر میشن.
من برای اینکه دوستان درک بهتری از موضوع پیدا کنن یک مسئله تخصصی رو یعنی افزایش حجم یک ALU رو روی یک تراشه ASIC یا FPGA خدمت دوستا نشون میدم.(البته تعریف از خود نباشه فک میکنم اولین بار در دنیا باشه که یک نفر با سنتز مدار به صورت عملی این مورد رو نشون میده (تعریف از خود نباشه : دی )
برای اینکه مسئله رو متوجه بشید من میخوام یک integer ALU رو طراحی کنم که با سنتز برنامه VHDL توسط xilinx ISE یک مدار با ضریب کلاک کل Data flow (به این معنا که ضریب alu با کل تراشه یکی هست) و یک مدار با ضریب کلاک خارج از data flow (در انودیا به صورت pumped clock) چه تاثیری بر حجم کلی این int ALU میگذاره.
خوب من با زبان VHDL یک ALU با مشخصه 8 دستور منطق(logic) و 8 دستور محاسبه (arithmetic) و البته ورودی های 8bit BUS برای ورودی و خروجی و البته یک selector 4bit برای سوئیچ روی دستورات دو بخش منطق و محاسبه ایجاد کردم.
متن برنامه VHDL نیازی نیست خدمت دوستان بدم(در صورت علاقه مندی دوستان بفرمایند من در pm خدمتشون میدم ) و برای شبیه سازی مدار هم از Xilinx ISE v8.2 استفاده شده.
تصویر زیر شماتیک مدار بدون ضریب کلاک اضافی خارج از جریان داده تراشه هست:
تصویر زیر شماتیک همان ALU با ضریب کلاک خارج از Data flow کل تراشه :
اینها سنتز XST شده یک برنامه VHDL برای یک ALU با 16 دستورالعمل هست -تفاوت 2 شماتیک تنها در یک کلاک اضافی برای ALU هست که تقریبا ابعاد تراشرو حداقل 45% اضافه کرده.(در شکل پیداه سازی تا 300% میتونه افزایش داشته باشه اما با بهینه سازی مداری ابعاد تراشه نهایتا 20% اضافه میشه)
اینکه حالا با انجام بهینه سازی ها میشه Pipline Stage هارو بسیار کاهش داد چیز مشخصی هست اما در کل طبق ازمایش بالا به وضوح متوجه شدیم ایجاد یک کلاک خارج از جریان داده تراشه موجب افزایش شدید حجم integrated circuit های مدار و افزایش بی مورد pipline stage ها برای ردگیری کلاک توسعه یافته میشه.
این توضیحات کاملا اضافی و در حد اکادمیک بود و در هیچ ریویو به اون اشاره نشده چون اینها در سطح دانشگاهی و embedded chip designer های این کاره کارشون برسی و شبیه سازی -بهینه سازی تراشه ها هست و اون ادیتور بدبخت شاید به عمرش اسم FPGA/CPLD ها به گوشش نخورده باشه چه برسه به شبیه ساز های تراشه های پیش ساخته بدون handcrafting design : دی
برگردیم به بحثمون و اینکه انودیا چگونه بدون افزایش زیاد ترانزیستور این همه هسته به sm ها اضافه کرده.
Eliminate Hotclock
یکی از تئوری ها و مسائل اصلی طراحی های انودیا از سری G80 یا GT200 با اسم رمز تراشه تسلا تا همین فرمی استفاده از واحد های اجرایی در فرکانسی بسیار بالاتر از کل تراشه با یک ضریب خاص بود.انودیا پیش تر اسم اون رو Shader Clock گذاشته بود و واحد های اجرایی execution Unite ها با ضریب ثابتی مثلا در فرمی 2x یا در نسل های پیشتر به ترتیب زیادتر تا 2.5x نسبت به فرکانس کل تراشه بیشتر بود.درواقع این سیستم که با نام double pumped شناخته میشود برای یک Execution unit به منظور 2 برابر کردن فرکانس هسته های اجرایی توسط اینتل از زمان NetBurst architecture شروع (همون معماری که در هسته های pentium 4 بکار رفت) و توسط انودیا از زمان نسل تسلا تا همین فرمی ادامه داشته.
حال در کپلر چه اتفاقی افتاده !!!
طبق نقشه راه مهندسین Nvidia معماری نسل اینده باید راندمان بی نهایت بالایی داشته باشه-طوری که طبق نقشه راه انودیا تا 5 الی 6 برابر نسل گذشته کارایی نسبت به توان برای معماری کپلر در نظر گرفته بشه.
طبق بیان NVIDIA's VP of GPU Engineering جناب اقای Jonah Alben ما اینو ساختیم پس بزارید بهبودش هم بدیم.
در این معماری به جای 2 برابر کردن هسته های اجرایی برای بازدهی بالاتر اومدن هسته های اجرایی رو چند برابر به نفع راندمان بالاتر کردن بنا بر این کل warp ها (در review فرمی که خیلی پیش تر ها داده بودم که متاسفانه بنا به دلایلی که البته خودم مقصر بودم به نام شخص دیگه ای ثبت شده توضیحات کامل warp هارو خدمت دوستان دادم)
باسیستم زمان بندی جدید در کل هسته ها issue و پخش میشن و بدون انجام کار با سرعت 2برابر front End همگام با اون منتظر روال بعدی warp ها میشن به این صورت تراشه به بازدهی بالاتر میرسه.
تصویر زیر قیاس کلی و بهبود های Elimination hotclock هست:
توضیحات:
1 : هر 2 هسته کپلر با pipline instruction مشابه بدون 2x clock تنها 1.8 برابر 1 هسته در فرمی رو داره(عملا هر هسته کپلر حدود 10% کوچکتر از هر هسته در فرمی هست)
توضیح: قطعا 2xclock موجب افزایش روال instruction pipline ها میشه و همین موجب افزایش 10% هر fermi cuda core نسبت به kepler cuda core میشه(در اثبات سنتز مدار alu بنده هم به نتیجه 45% افزایش رسیدیم که البته بدون بهینه سازی مدار بود)
2 : هر 2 هسته موجود در کپلر به اندازه 90% توان مصرفی 1 هسته در فرمی مصرف داره بنابراین عملا این حرکت انودیا مهر ختمی بود برا shaderclock ها.
3 : وقتیکه ما حرف سرعت کلاک رو هم بیاریم وسط باز هم اختلاف عمیق تر میشه و اینجا 2 هسته کپلر 50% 1 هسته انودیا در کلاک مشابه مصرف دارن.
خوب این تازه گوشه ای از اعمال تغییرات مهندسین انودیا بود - حرکت بعدی اعمال تغییرات در سلسله روال زمان بندی بخش front End هست که در بخش بعد خدمت دوستان صحبت میکنم
در این بخش متوجه میشیم که چرا افزایش 3 برابری هسته ها لزوما به صورت خطی موجب افزایش 3 برابری کارایی نشده.
SW scheduling Front End
در علوم کامپیوتری و معماری تراشه ها و میکروپروسسور ها عموما از دو طرف میشه به تراشه ها نگاه کرد :
الف:بخش کنترلی تراشه
ب: بخش اجرایی تراشه
توضیح الف: بخش کنترلی و اعمال داده یک هسته مستقل که میتونیم اون رو Front End یا حتی در موارد ساده تر Control Unite بنامیم - بخشی هست که به طور کلی میتونیم مراحل زیر رو برای اون متصور بشیم:
1: ابتداوظیفه واکشی ترد ها (fetch)
2: برداشت اونها از کاشه دستورالعمل(inst catch) و ترجمه دستوزالعمل (instruction decoding)
3: صف بندی و زمان بندی ارجاع دستورالعمل ها (schaduling)
4: ارجاع دستورات زمان بندی شده به واحد اجرایی (issue)
توضیح ب: بخش اجرایی در واقع وضیفه excute دستورات ارسالی از طرف Front End رو داره و بخش اجرایی کارامد است که به بهترین نحو وظایف ارسالی از طرف CU رو به انجام برسونه.
تمامی تراشه ها و پردازنده ها از منطق ساده بالا پشتیبانی میکنن (هرچند در بعضی منطق طراحی تراشه ها قسمت هایی حذف و یا قسمت هایی اضافه میشه اما روال کار معمولا یکی هست)درواقع اصل اساسی بالا معتبر هست و در جزئیات تفاوت ها ایجاد میشود - مثل تکنولوژی های اینتل در پردازنده های خود برای به حداکثر رسوندن IPC که اینجا مجالی برای توضیح اونها نیست و ربطی هم به این تاپیک نداره (اگر استقبال بشه بعدا در اون مورد هم صحبت میکنیم).
مهندسین طراح پردازشگر ها معمولا چندین راه برای اعمال متد پردازشی بالا رو دارن و این متد ها رو شاید بشناسید .در این مقاله مجالی برای توضیح انواع اونها نیست من فقط به منطق Nvidia و نسل پیشین و مقایسه اون با کپلر میپردازم.
--------------------------------------
در منطق زمان بندی دستورالعمل ها برای اجرا در تراشه های قدیم و جدید ( مراحل 2 و3 ) مهندسین طراح همیشه 2 راه رو پیش روی خودشون داشتن
static scheduling
در این متد زمان بندی دستورات و طبقه بندی و اسال اونها طبق یک جدول از پیش تایین شده instruction info که توسط نرمافزار software به تراشه همراه با اطلاعات operand ها و instruction ها هست ارسال میشه و عملا front end تنها وظیفه ورپ سازی و ارسال اونها رو به execution units ها داره (توضیح دقیق ترشو از دید ML در ادامه خدمت دوستان میدم):
1 : در این حالت تراشه بشدت شکل intensively compiler به خودش میگیره و درواقع توان autonomously processing خودش رو بشدت از دست میده و به برنامه نویسان و کارایی بهینگی استفاده از پردازنده برای زمان بندی اونها محتاج میشه.
2: کار برنامه نویسان و درایور سازان برای بهینگی درایور زمانبند توسط پردازنده برای اون تراشه بسیار بسیار مشکل میشه چون باید بهترین حالت بهینگی نرم افزار رو برای تراشه ایجاد کنن که عملا با حجم وسیع محصولات در PC عملا این کار بی نهایت دشوار تر هم میشه.(تمام اینها به منظور زمان بندی صحیح و بهینه توسط درایور هست)
3:درصورت بهینگی ارجاع و زمانبندی دستورالعمل ها قدرت تراشه میتونه به صورت خطی افزایش پیدا کنه(توان تراشه در صورت بهینگی ارجاع دستورات به شکل غیرقابل تصوری بالا میره چیزی که در کنسول های بازی میبینیم)
4: این سیستم موجب کاهش پیچیدگی Front End میشه در نتیجه در die size اختصاصی واحد کنترل میتونن صرفه جویی کنن.
5: کاهش autonomously processing به معنای از دست دادن حدی قدرت محاسباتی computing capibility هست(که البته در گیمینگ تاثیری نداره).چون تراشه عملا به طیف وسیع و متفاوت دستورالعمل ها نمیتونه واکنش مناسب بده و نیازی به برنامه ریزی مستقیم تراشه برای کارکرد منسب به ازای هر دستور متغیر هست و این برای داده های محاسباتی پیشچیده اصلا مناسب نیست.
HardWare scheduling
در این متد بخش Front End طوری طراحی میشه که حدالمکان بتونه به صورت مسقل تمامی وظایف زمانبندی و چک instruction dependency و ...رو به صورت خودمختار انجام بده ( هر چند اصل کار رو پردازنده از طریق اعمال درایور انجام میده و توضیحات تکمیلی در ادامه متن خدمت دوستان میدم) :
بیاید به مزایا و معایب این سیستم نگاهی کنیم:
1: در این حالت تراشه خودمختار تر از SW scheduling هست
2: برنامه نویسان کار راحت تری برای بهنگی نرم افزار ها روی تراشه دارن چون عمده کار رو بخش Front End تراشه به عهده داره.سرعت بهینگی نرمافزار ها برای تراشه بهبود زیادی نسبت به متد قبلی داره.
3: چون بخش Front End خود وظیفه چک وابتگی دستورالعمل ها و ایجاد جدول زمانبدی دستورات رو داره عملا Front End به کلاک های بیشتری برای ایجاد ریسمان (warp) های مناسب برای تغذیه Execution unite ها نسبت به مدل قبلی داره.یعنی در صورت بهینگی دستورات برای حالت قبل عملکرد تراشه با SW method بسیار چشمگیرتر خواهد بود.
4:این سیستم موجب افزایش پیچیدگی و مدار های داخلی برای CU هست که بتونه به صورت خودمختار (Autonomously) دستورات رو dependency checking و scheduling کند.
5: افزایش autonomously processing به معنای بدست اوردن حدی قدرت محاسباتی Compute در تراشه هست.چون تراشه عملا به طیف وسیع و متفاوت دستورالعمل ها میتونه واکنش مناسب بده و نیازی به برنامه ریزی نداشته باشه.
این بود شکل کلی این روال ها که قاعدتا عینن در GPU ها اجرا نیمشه اما شباهت هایی داره که بعدا خدمت دوستان عرض میشه.
در کپلر چه اتفاقی افتاده؟خوب اگر بخوایم منصافنه بگیم
This architecture is not compute compatible
it's just for effeciency
it's just for effeciency
خوب پیش از هرچیزی باید بگیم مهندسین انودیا در کپلر تصمیم گرفتن متد SW scheduling رو پیاده سازی کنن.برای فهم بیشتر به تصویر زیر دقت کنید:
در تصویر بالا شما شاهد نحوه قرار گیری بلاک و سیستم زمانبند در فرمی و کپلر هستیداگر بخوایم برای توضیح از نسل قبل فرمی شروع کنیم باید بگیم سیستم HW scheduling تراشه ای مثل GF114 در بخش FRONT End نه تنها قادر به انجام کار های پایه ای زمانبدی مثل scoreboarding (منظور از scoreboarding نگاهداری ریسمان warp هایی است که روی مموری در انتظار دسترسی به واحد های اجرایی هستن یا باقی عملیات هایی که تاخیر زیادی دارن) و یا انتخاب و برداشت warp ها از بخش pool ریسمان ها برای اجرا بود بلکه علاوه بر اینها Front End فرمی مسئول زمانبندی خود دستورالعمل های موجود در ریسمان ها هم بود.
این مورد در فرمی عملا موجب میشد که تراشه قادر به انجام اعمال محاسباتی با حد تغییر زیاد دستورالعمل ها به خاطر پیچیدگی FE اون باشه.پیچیدگی Front End برای تراشه ای که تعداد کمی واحد زمانبند در تراشه خود داراست عامل مهمی محسوب نمیشه .
اما این پیچیدگی که موجب پایین امدن power and area efficiency میشود برای تراشه ای که 32 واحد زمانبند در سطح تراشه خود دارا هست عملا موجب افزایش شدید سطح تراشه وپایین امدن بازدهی اون میشه و این برای کپلر GK104 غیر قابل قبول هست.
به همین علت براورد مهندسین nVIDIA برای کپلر استفاده از همین static scheduling هست تا به power and area efficiency بالایی برای تراشه برسن.
برای توضیح و فهم بیشتر و اینکه این مورد در GPU ها چگونه هست متن زیر رو با دقت بخونید:
به طور سنتی (در نسل فرمی الاخصوص) پردازنده با توجه به دستورات درایور شروع به ساخت یک روال ثابت زمانبندی static scheduling میکنه و سپس اون ها رو به واحد های زمانبندی سخت افزاری GPU میفرسته که این باعث افزایش پیچیدگی هم بخش Hardwrae و هم software میشود(هرچند بخش software نسبت به حالت تماما نرمافزاری کار راحت تری رو پیش رو داره).به طور کلی Hardware instruction scheduling به پردازنده اجازه میده به بهترین روش ممکن و با بالاترین بازدهی که اجازه داده میشه به صورت real time دستورات رو زمانبندی کنه بدون در نظر گرفتن به روال موکد دستور دهی خودش دستورات رو زمان بندی میکنه.این به نوبه خودموجب افزایش بازدهی پردازنده میشه.
(معذرت میخوام اگر کمی مشکل هست بحث بالا اگر سوالی بود در ادامه تاپیک خوشحال میشم بپرسید)
خوب طبق صحبت های بالا Hardware scheduling بسیار عالی هم هست-اما تحقیقات اخیر محققین انودیا چیز دیگه ای رو نشون داده:در ادامه به این میپردازیم:
تحقیقات و شبیه سازی های معماری اخیر انودیا نشون داده که HW scheduling میزان منصفانه ای از مصرف رو در ازای فواید ناچیز در تراشه به ارمغان میاره -به طور خاص چون Pipeline math های کپلر دارای تاخیر های ثابت هستن(نسبت به نسل قبل execution unit ها در نصف فرکانس کار میکنن پس عملا این تاخیر موجهه) بنابر این وجود HW Scheduling درون سیستم warp ها(ریسمان ها) عملا زاید هست چون کامپایلر تراشه میدونه زمان تاخیر صدور هر دستورالعمل محاسباتی چقدر هست.
بنابراین انودیا تصمیم گرفت به جای زمانبند های پیچیده سخت افزاری complex scheduler اونهارو باز مانبند های ساده ای که هنوز از scoreboarding و دیگر متد های زمانبدی داخلی ورپ ها استفاده میکند جایگزین کند.به بیان دیگر زمانبندی ورپ ها توسط کامپایلر یعنی برگشتن انودیا به سیستم قدیم static scheduling .
سیستم sw scheduling در برابر hw scheduling با تمام ویژگی های مفیدش عملا باعث میشه تراشه در مقابله با complex compute applications دچار مشکل باشه(در بالا خدمت دوستان عرض کردم) به همین علت بود که در فرمی با استفاده از اون سیستم انودیا تراشه هایی رو مناسب با COMPUTE و GPGPU طراحی کرده بود و AMD هم با معماری GCN و استفاده از HW scheduling عملا به دنبال راه قدیم انودیا بود.
اما انودیا فعلا تصمیم گرفته برای هر بخش تراشه هایی متناسب با اون زمینه تولید کنه و این یعنی برای gpgu هم انودیا برنامه هایی روداره.
سیستم SW scheduling در صورت صحت عملکر کامپایلر میتونه انقلابی رو در استفاده از قدرت تراشه ایجاد کنه-تنها مشکل این هست که تاثیر درایور ها بر روی قدرت تراشه رو بسیار چشمگیر تر از گذشته ها میکنه.
همونطور که میدونید کپلر GK104 تا 3 برابر هسته های GTX580 رو داره اما عملا قدرت هسته ها به صورت خطی افزایش پیدا نکردن-اما این پتانسیل وجود داره که در صورت بهینگی استفاده از هسته ها این تراشه قدرت خودش رو نشون بده.
توضیحات تفاوت سیستم هایی که ساماریتن روی اونها اجرا شده رو در تصویر میبینید-کلا تراشه هایی که سیستم sw Scheduling أارن برای کنسول ها بسیار مناسب هستن چون میتونن بازی رو برای یک محصول و تراشه بسیار بهینه سازی کنن هرچند در سیستم HW scheduling هم امکان پذیره و حتی بهتر اما کمبود Effeciency این سیستم ها عملا اجازه نمیده اونها در این قسمت زیاد موفق باشن.
البته دموی ساماریتن روی کپلر با تکنیک FXAA اجرا شده بود که باعث میشد Memmory tax برنامه بسیار کاهش پیدا کنه و 2GB رم GTX680 برای این دمو کافی به نظر برسه.
برگردیم سر ادامه بحثمون:
حال بهتره از دید مالتی پروسسور به تراشه نگاه کنیم و اون رو با GF114 مقایسه کنیم:
به تصویر زیر که شمایی از یک sm در GF104/114 هست نگاهی بیندازید:
خوب همونطور که در بالا هم عرض کردم در سیستم SM موجود در GF104 با توجه به اینکه متد ILP توسط HW scheduling چک میشه برخلاف GK104 که از طریق نرم افزار و کامپایلر با جدول ثابت هست بنابر این نمیتونیم بخش Front End اونو مستقیما به gk14 تامیم بدیم اما باز هم مناسب تر از GF100 هست.
در این SM منابع عملیاتی اجرایی تراشه به 3 گروه 16 تایی کودا که فقط یکی از اونها قابلیت اجرای دستورات Fp64 رو داره تقسیم میشه و گرو های تابعی دیگر رو هم که مجموعا 7 گرو هستن میتونید مشاهده کنید:
GF104/GF114 SM Functional Units
16 CUDA cores (#1)i
16 CUDA cores (#2)i
16 CUDA cores, FP64 capable (#3)i
16 Load/Store Units
16 Interpolation SFUs (not on NVIDIA's diagrams)i
8 Special Function SFUs
8 Texture Units
خوب کارایی بخش های اون رو پیشتر در مقاله فرمی خدمت دوستان توضیحات مفصل دادم(دوستانی که اصل مقاله فرمی رو بدون اضافات و مهملاتی..... مثل به باور من یا فوق تخصصی و ........ که از شاهکار های اون دوست گرامیمون هست و البته عکس های با رزولوشن بالا بدون گذاشتن Vfsdf در گوشه عکس ها میخوان بفرمایند در Pm خدمتشون فایل word اصلی رو بدم)
حال به شمایی از یک smx در GK104 بهتره نگاهی بندازیم:
برخلاف نسل پیش که تنها 7 بخش اجرایی عملیاتی تابعی functional units وجود داشت در smx کپلر ما شاهد 15 بخش functional units هستیم به این معنا که زمانبند ریسمان ها warp cheduler ها میتونن 15 بخش functional رو فراخوانی کنن.
عملا 2 برابر شده منابع اجرایی و تابعی در کپلر GK104 نسبت به نسل قبلی GF104/114 به انودیا اجازه میده shaderclock رو که فرکانس منابع اجرایی رو 2 برابر میکرد خیلی راحت و بدون هیچ مشکلی حذف کنه و اصلا احساس کمبود منابع عملیتاری ور هم نکنه.
در زیر به ترتیب واحد های functional units رو میبینید:
GK104 SMX Functional Units
32 CUDA cores (#1)i
32 CUDA cores (#2)i
32 CUDA cores (#3)i
32 CUDA cores (#4)i
32 CUDA cores (#5)i
32 CUDA cores (#6)i
16 Load/Store Units (#1)i
16 Load/Store Units (#2)i
16 Interpolation SFUs (#1)i
16 Interpolation SFUs (#2)i
16 Special Function SFUs (#1)i
16 Special Function SFUs (#2)i
8 Texture Units (#1)i
8 Texture Units (#2)i
8 CUDA FP64 cores
اگر به SMX دقت کنید 4 زمانبند ریسمان warp schedulers وجود داره که میتونن در هر سیکل ساعت 2 دستورالعمل رو در صورت احراز شرایط ILP (منظور Instruction level parallelismهست که در اون وابستگی دستورات بر طبق اصل super scaler ای چک میشه که از وظایف HW/SW dependency cheking هست) رو فراخوانی کنه یعنی اگر تمام شرایط ILP صادق باشه هر 4 زمانبند میتونن 8دستورالعمل رو بز I-set catch برای ریسمان سازی فراخوانی کنن و به توابع اجرایی ارسال کنن
texture unite
 [/IMG]
[/IMG]
از طرف دیگه تعداد texture unite ها دقیق 2 برابر شده و این برای کل تراشه از 64 در نسل قبل به 128 در نسل فعلی رسیده که عملا خیلی بیش از ظرفیت FFU هایی است که باید روال Graphic pipline رو در تراشه اعمال کنن.(منظور از کم بودن ffu کم بودن تعدادsm هاست و هر ffu شامل همون poly morph انجین میشه که به ازای هر sm فقط 1 پولیمورف انجین وجود داره.
Bindless Textures
به همین علت انودیا سیستم جدیدی رو برای تکسچر ها برنامه ریزی کرده به نام Bindless Textures تا بتونه نهایت توان تغذیه تکسپر هارو داشته باشه(برای 2 برابر واحد تکسچر نسبت به نسل قبل).درک چگونگی کار کرد این سیستم به تصویر زیر دقت کنید:
در گذشته و نسل های پیش از کپلر هر sm میتونست برابر 128 عدد تکسچر رو هزمان برای انجام اعمال graphic pipline فراهم کنه اما با سیستم جدید تراشه میتونه عملا در طول shader code ها هر مقدار تکسچر(بالغ بر 1 میلیون تکسچر) رو همزمان فراهم کنه و این به قول bsn یکی از کلیدی ترین دلایلی بود که دموی عظیم samaritan تنها بر روی یک کارت تونست اجرا بشه.
البته AMD هم از سیستم جدید به نام Partially Resident Textures, i.e. MegaTexturing technology با رهبری JOHN CARMACK کبیر برای موتور های OpenGL خودش بهینه بوده پرده برداری کرد که به نظر Bsn در جای خودش محترم هست اما در برابر سیستم جدید انودیا چون ورای محدودیت هایOpenGL limited هست سیستم کارامدتری میاد.(هر کدوم از اینها جای بحث زیادی دارن و در حوصله این مقاله نمیگنجه)
خوب حل بیاید کل تراشه هارو با هم مقایسه کنیم:
شمای کلی GF104/114 که در زیر میبینید:
شمای کلی GK104 که در زیر میبینید:
خوب مشخصه های تراشه واضح هست و من نیازی نمیبینم که اون هارو چندین بار تکرار کنم در شکل زیر میتونید ببنید:
تنها نکات قابل عرض در سطح SM ها وجود نسل 2 FFU های انودیا برای DX11 یعنی Plymorph Engine 2 هست که انودیا این بخش رو برای تراشه های نسل جدید از نوع بهینه سازی کرده.
polymorph Engine 2
در شکل زیر میتونید شمای polymorph Engine 2 رو ببنید:
انودیا در واقع با PE 2 سعی کرده نیاز اساسی 3-4 برابر شدن هسته های هر SM رو برای پوشش روال Graphic pipline پوشش بده - این بخش از تراشه هنوز 5 مرحله graphic pipline یعنی از مرحله Vertex Fetch تا مرحله Stream Output که هر یک از این مراحل توسط هسته های پردازشی SMX پردازش و توسط این Stage ها مرتبط میشن.
درواقع تفاوت اصلی این نسل از polymorph enginde ها با نسل گذشته ازفیش شدید بازدهی جریان داده data stream efficiency هست . به بیا دیگر نرخ مقادیر اولیه throughput داده ها (primitive rates) در نسل جدید بالغ بر 2 برابر نسل پیش هست که اجازه میده data through put به درون هسته ها تا 4 برابر نسل پیش افزایش پیدا کنه و عملا کارایی تسلیشن تنها بهبتونه به 4 برابر نسل پیش(فرمی) برسه.
more internal connection =more data transfer
انودیا با عرضه کپلر ادعا کرده که بالاترین نرخ تبادل داده رو در تراشه تا به حال به نام خودش ثبت کرده:
بدون کنترلر مموری کارامد هیچ تراشه ای موفق نیست -این مهم نیست که تراشه شما چقدر سریع هست - مهم اینه که هسته های اجرایی شما گرسنه نمانند-برخلاف پردازنده ها memmory controller یکی از مهمترین بخش های GPU محسوب میشه - بدون سرعت کافی اون Catch hirarchy نمیتونه روال خودش رو همگام با سرعت بالای هسته ها پیش ببره بنا بر این هسته ها دچار معضل گرسنگی میشن.
در واقع یکی از علل شکست Intel Larrabee و ATI R600 همین ناکارامد بودن memmory controller effeciency بود.
چگونه انودیا به این رقم دست پیدا کرده ؟؟
به تصویر زیر دقت کنید:
برای انجام مناسب سلسله روال دسترسی هسته ها به مموری-انودیا با ایجاد cache hierarchy موثر و سطح عظیم internal memmory connections در سطح تراشه از زمان فرمی و ارتقائ اون در کپلر عملا به بالاترین حد راندمان عملکرد حافظه تا به اکننون رسیده.
خوبه بدونید کارتی مثل gtx680 در 1.50 GHz QDR عمل میکنه و در مقام مقایسه تراشه 384bit ای high end AMD یعنی Tahiti در 1.375 GHz QDR عمل میکنه که البته رقم بدی نیست (حدود5500 mhz effective هست)
هسته های متعدد و بسیار زیاد نسل کپلر نیاز به تغذیه بالایی دارن و عملا این میزان پهنای باند هسته ای اجرایی رو دچار معضل گرسنگی نمیکنه.
--------------------
این بود مروری بر معماری نسل نوین کپلر GK104 انودیا که امیدوارم کافی بوده باشه- سعی کردم مقاله جلوتر از اکثر ریوی های خارجی و کامل تر و اساسا روی اصل موضوعات تخصصی باشه
در بخش بعد به ویژگی های جدید معرفی شده همزمان با کپلر مثل Adjusment Vsync و Txaa و ..... میپردازم تا ببنیم اونها چگونه به افزایش قابلیت های این تراشه کمک میکنن.
اگر سوالی بود حتما پرسیده بشه چون این مقاله تنها جنبه تخصصی و برسی معماری تراشه رو داشت و قصدم از این ریویو برسی بنچمارک ها نبود.
امیدوارم مفید بوده باشه.
منابع :
bsn
annadtech
hardwarecanucks
hexus
در بخش شبیه سازی و اکثر توضیحات تکنیکی هم بنده حقیر
موفق باشید


 Google
Google